Flink 内存类型相关疑问


|
Hi all, 我是Flink新人,最近在看一些flink资源管理机制的知识,有3个内存类型方面的问题想请教大家: 1. Flink的内存类型如下图1所示,其中Heap内存和NonHeap内存由JVM管理,我想问一下Direct内存是否也是由JVM管理?因为我同时也看到过图2所示的内存类型,上面标示的是JVM Direct,但在FLIP102里看到的是属于Outside JVM,所以现在有点困惑。另外,我从相关页面上只看到了Network buffers, Managed memory, Heap的计算方法,但不知道按照图1所示的内存类型,Direct内存和NonHeap是怎么计算分配的?  图1 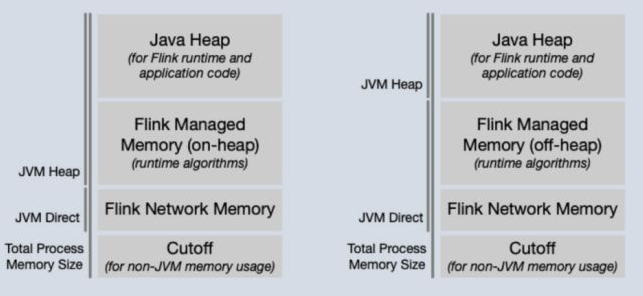 图2 2. Flink metrics里展示的内存方面的信息以Status.JVM.Memory为前缀,包含Heap, NonHeap, Direct, Mapped四种。我测试过,这四种内存Used之和应该并不是TM真正所使用的总内存。那么TM使用的总内存还包括哪些,是在哪里用到的?(不知道是不是cut-off那部分使用的内存?)Flink 1.10似乎对内存进行了更细致的划分和分配,但在metrics里展示的内配置和使用信息还是跟1.9一样的么? 3. Window相关的算子会将窗口内的数据作为状态保存在内存里,等待窗口触发再进行计算。想问一下这里的状态是存在哪种类型的内存里面? 祝好,
|
|
|
Hi, 关于你的几个问题: 1. 关于 JVM 的内存,堆内存(Heap Memory)的定义通常是比较清晰的,但堆外/非堆内存(Off-Heap/Non-Heap Memory)的定义却有很多不同的版本,这应该是导致你困惑的主要原因。让我们先抛开这些名词,本质上 Java 应用使用的内存(不包括 JVM 自身的开销)可以分为三类:
Direct 内存是直接映射到 JVM 虚拟机外部的内存空间,但是其用量又受到 JVM 的管理和限制,从这个角度来讲,认为它是 JVM 内存或者非 JVM 内存都是讲得通的。 关于 Off-Heap/Non-Heap,广义上讲只要不是 Heap 内存就可以称为 Non-Heap,但是我们经过实验发现 MXBean 的 Non-Heap 是不包括 Direct,而是由 Code Cache、Metaspace、Compressed Class Space 几个部分组成。FLIP-102 讨论的是 metrics 如何在 WebUI 上展示,Flink metrics 是通过 MXBean 获取的,因此图一展示的 Non-Heap 是与 MXBean 的 Non-Heap 定义的。 2. Heap/Non-Heap 前面已经介绍过,而 Direct/Mapped 则同样是通过 MXBean 统计两个 Buffer Pool 的情况。这里的 Direct 指的是 Direct Buffer Pool 而不是 Direct Memory,这两个 Buffer Pool 都是受 -XX:MaxDirectMemorySize 控制的,可以认为都是 Direct Memory 的一部分。 这几个 metrics 加在一起不是 TM 的总内存,一方面是因为 Native 内存没有被算进去(也就是 Cut-off 的主要部分),因为 Native 是不受 JVM 管理的,MXBean 完全不知道它的使用情况。另一方面,JVM 自身的开销也并不是都被覆盖到了,比如对于栈空间,JVM 只能限制每个线程的栈空间有多大,但是不能限制线程的数量,因此总的栈空间大小也是不受控制的,也没有通过 Metric 来体现。 总的来说,JVM 的内存机制是非常复杂的,且并不是每一个部分都能够由用户参数控制的。Flink 1.10 简化了内存模型,目的是让用户不需要去关心这其中的细节,只关注 Flink 各功能模块所需的相关内存大小即可。而目前在 1.10 中的 metric 是比较缺失的无法完全描述 Flink 的内存使用情况,社区提出 FLIP-102 梳理 metrics 及 UI 展示也正是为了解决这个问题。但即便如此,受 JVM 内存机制本身的限制,恐怕也很难做到每个部分都完全匹配到对应的 metrics 上。 3. 这个应该是存在 state 里的,具体用哪种类型的内存取决于你的 State Backend 类型。MemoryStateBackend/FsStateBackend 用的是 Heap 内存,RocksDBStateBackend 用的是 Native 内存,也就是 1.10 中的 Manage Memory。 Thank you~ Xintong Song On Sun, Mar 8, 2020 at 4:49 PM pkuvisdudu <[hidden email]> wrote:
|
|
|
非常详细的解答,非常感谢~~
还有一些小疑问。图1中的Direct类型里面所包含的framework offheap、task offheap以及shuffle就是您讲的“不在 JVM 堆上但受到 JVM 管理的内存:Direct”么?这部分内存是可以知道其使用情况并在metrics里看到的么? 另外,flink 1.10里将RocksDBStateBackend改为使用managed memory,不过网页上显示的是managed memory统一使用offheap内存,您的解答里说的是native内存,不知道是不是您说的“完全不受 JVM 管理的内存:Native”这个?不是太清楚offheap和direct以及native的关系是怎样的 最后,我在官网上看managed memory和network buffers在作业启动后会有变化,但我一直看不懂是咋变化的😂,不知道这里能否解答一下 再次感谢详细的解答~~ | | 张江 | | 邮箱:[hidden email] | 签名由 网易邮箱大师 定制 在2020年03月09日 11:22,Xintong Song 写道: Hi, 关于你的几个问题: 1. 关于 JVM 的内存,堆内存(Heap Memory)的定义通常是比较清晰的,但堆外/非堆内存(Off-Heap/Non-Heap Memory)的定义却有很多不同的版本,这应该是导致你困惑的主要原因。让我们先抛开这些名词,本质上 Java 应用使用的内存(不包括 JVM 自身的开销)可以分为三类: JVM 堆内存:Heap 不在 JVM 堆上但受到 JVM 管理的内存:Direct 完全不受 JVM 管理的内存:Native Direct 内存是直接映射到 JVM 虚拟机外部的内存空间,但是其用量又受到 JVM 的管理和限制,从这个角度来讲,认为它是 JVM 内存或者非 JVM 内存都是讲得通的。 关于 Off-Heap/Non-Heap,广义上讲只要不是 Heap 内存就可以称为 Non-Heap,但是我们经过实验发现 MXBean 的 Non-Heap 是不包括 Direct,而是由 Code Cache、Metaspace、Compressed Class Space 几个部分组成。FLIP-102 讨论的是 metrics 如何在 WebUI 上展示,Flink metrics 是通过 MXBean 获取的,因此图一展示的 Non-Heap 是与 MXBean 的 Non-Heap 定义的。 2. Heap/Non-Heap 前面已经介绍过,而 Direct/Mapped 则同样是通过 MXBean 统计两个 Buffer Pool 的情况。这里的 Direct 指的是 Direct Buffer Pool 而不是 Direct Memory,这两个 Buffer Pool 都是受 -XX:MaxDirectMemorySize 控制的,可以认为都是 Direct Memory 的一部分。 这几个 metrics 加在一起不是 TM 的总内存,一方面是因为 Native 内存没有被算进去(也就是 Cut-off 的主要部分),因为 Native 是不受 JVM 管理的,MXBean 完全不知道它的使用情况。另一方面,JVM 自身的开销也并不是都被覆盖到了,比如对于栈空间,JVM 只能限制每个线程的栈空间有多大,但是不能限制线程的数量,因此总的栈空间大小也是不受控制的,也没有通过 Metric 来体现。 总的来说,JVM 的内存机制是非常复杂的,且并不是每一个部分都能够由用户参数控制的。Flink 1.10 简化了内存模型,目的是让用户不需要去关心这其中的细节,只关注 Flink 各功能模块所需的相关内存大小即可。而目前在 1.10 中的 metric 是比较缺失的无法完全描述 Flink 的内存使用情况,社区提出 FLIP-102 梳理 metrics 及 UI 展示也正是为了解决这个问题。但即便如此,受 JVM 内存机制本身的限制,恐怕也很难做到每个部分都完全匹配到对应的 metrics 上。 3. 这个应该是存在 state 里的,具体用哪种类型的内存取决于你的 State Backend 类型。MemoryStateBackend/FsStateBackend 用的是 Heap 内存,RocksDBStateBackend 用的是 Native 内存,也就是 1.10 中的 Manage Memory。 Thank you~ Xintong Song On Sun, Mar 8, 2020 at 4:49 PM pkuvisdudu <[hidden email]> wrote: Hi all, 我是Flink新人,最近在看一些flink资源管理机制的知识,有3个内存类型方面的问题想请教大家: 1. Flink的内存类型如下图1所示,其中Heap内存和NonHeap内存由JVM管理,我想问一下Direct内存是否也是由JVM管理?因为我同时也看到过图2所示的内存类型,上面标示的是JVM Direct,但在FLIP102里看到的是属于Outside JVM,所以现在有点困惑。另外,我从相关页面上只看到了Network buffers, Managed memory, Heap的计算方法,但不知道按照图1所示的内存类型,Direct内存和NonHeap是怎么计算分配的? 图1 图2 2. Flink metrics里展示的内存方面的信息以Status.JVM.Memory为前缀,包含Heap, NonHeap, Direct, Mapped四种。我测试过,这四种内存Used之和应该并不是TM真正所使用的总内存。那么TM使用的总内存还包括哪些,是在哪里用到的?(不知道是不是cut-off那部分使用的内存?)Flink 1.10似乎对内存进行了更细致的划分和分配,但在metrics里展示的内配置和使用信息还是跟1.9一样的么? 3. Window相关的算子会将窗口内的数据作为状态保存在内存里,等待窗口触发再进行计算。想问一下这里的状态是存在哪种类型的内存里面? 祝好, |
|
|
>
> 图1中的Direct类型里面所包含的framework offheap、task offheap以及shuffle就是您讲的“不在 JVM > 堆上但受到 JVM 管理的内存:Direct”么? 是的 > 这部分内存是可以知道其使用情况并在metrics里看到的么? 应该是与metrics中的Direct是对应的(因为绝大多数情况我们没有使用Mapped Buffer),这里细节我记不太清楚了最好再确认下。 另外,flink 1.10里将RocksDBStateBackend改为使用managed memory,不过网页上显示的是managed > memory统一使用offheap内存,您的解答里说的是native内存,不知道是不是您说的“完全不受 JVM 管理的内存:Native”这个? 是的 不是太清楚offheap和direct以及native的关系是怎样的 Flink 配置项中的 task/framework offheap,是包括了 direct 和 native 内存算在一起的,也就是说用户不需要关心具体使用的是 direct 还是 native。 最后,我在官网上看managed memory和network buffers在作业启动后会有变化 能把具体的页面链接发一下吗,可能指的是1.9以前的情况,1.10是不会变化的。1.9以前的话,TM会在进程启动并初始化之后触发一次GC,然后以GC后的空闲内存作为Heap内存重新算一遍managed、network内存应该多大。 Thank you~ Xintong Song On Mon, Mar 9, 2020 at 3:23 PM pkuvisdudu <[hidden email]> wrote: > 非常详细的解答,非常感谢~~ > > 还有一些小疑问。图1中的Direct类型里面所包含的framework offheap、task offheap以及shuffle就是您讲的“不在 > JVM 堆上但受到 JVM 管理的内存:Direct”么?这部分内存是可以知道其使用情况并在metrics里看到的么? > > 另外,flink 1.10里将RocksDBStateBackend改为使用managed memory,不过网页上显示的是managed > memory统一使用offheap内存,您的解答里说的是native内存,不知道是不是您说的“完全不受 JVM > 管理的内存:Native”这个?不是太清楚offheap和direct以及native的关系是怎样的 > > 最后,我在官网上看managed memory和network > buffers在作业启动后会有变化,但我一直看不懂是咋变化的😂,不知道这里能否解答一下 > > 再次感谢详细的解答~~ > > > > > | | > 张江 > | > | > 邮箱:[hidden email] > | > > 签名由 网易邮箱大师 定制 > > 在2020年03月09日 11:22,Xintong Song 写道: > Hi, > > > 关于你的几个问题: > > > 1. 关于 JVM 的内存,堆内存(Heap Memory)的定义通常是比较清晰的,但堆外/非堆内存(Off-Heap/Non-Heap > Memory)的定义却有很多不同的版本,这应该是导致你困惑的主要原因。让我们先抛开这些名词,本质上 Java 应用使用的内存(不包括 JVM > 自身的开销)可以分为三类: > JVM 堆内存:Heap > 不在 JVM 堆上但受到 JVM 管理的内存:Direct > 完全不受 JVM 管理的内存:Native > Direct 内存是直接映射到 JVM 虚拟机外部的内存空间,但是其用量又受到 JVM 的管理和限制,从这个角度来讲,认为它是 JVM 内存或者非 > JVM 内存都是讲得通的。 > > > 关于 Off-Heap/Non-Heap,广义上讲只要不是 Heap 内存就可以称为 Non-Heap,但是我们经过实验发现 MXBean 的 > Non-Heap 是不包括 Direct,而是由 Code Cache、Metaspace、Compressed Class Space > 几个部分组成。FLIP-102 讨论的是 metrics 如何在 WebUI 上展示,Flink metrics 是通过 MXBean > 获取的,因此图一展示的 Non-Heap 是与 MXBean 的 Non-Heap 定义的。 > > > 2. Heap/Non-Heap 前面已经介绍过,而 Direct/Mapped 则同样是通过 MXBean 统计两个 Buffer Pool > 的情况。这里的 Direct 指的是 Direct Buffer Pool 而不是 Direct Memory,这两个 Buffer Pool 都是受 > -XX:MaxDirectMemorySize 控制的,可以认为都是 Direct Memory 的一部分。 > > > 这几个 metrics 加在一起不是 TM 的总内存,一方面是因为 Native 内存没有被算进去(也就是 Cut-off 的主要部分),因为 > Native 是不受 JVM 管理的,MXBean 完全不知道它的使用情况。另一方面,JVM 自身的开销也并不是都被覆盖到了,比如对于栈空间,JVM > 只能限制每个线程的栈空间有多大,但是不能限制线程的数量,因此总的栈空间大小也是不受控制的,也没有通过 Metric 来体现。 > > > 总的来说,JVM 的内存机制是非常复杂的,且并不是每一个部分都能够由用户参数控制的。Flink 1.10 > 简化了内存模型,目的是让用户不需要去关心这其中的细节,只关注 Flink 各功能模块所需的相关内存大小即可。而目前在 1.10 中的 metric > 是比较缺失的无法完全描述 Flink 的内存使用情况,社区提出 FLIP-102 梳理 metrics 及 UI > 展示也正是为了解决这个问题。但即便如此,受 JVM 内存机制本身的限制,恐怕也很难做到每个部分都完全匹配到对应的 metrics 上。 > > > 3. 这个应该是存在 state 里的,具体用哪种类型的内存取决于你的 State Backend > 类型。MemoryStateBackend/FsStateBackend 用的是 Heap 内存,RocksDBStateBackend 用的是 > Native 内存,也就是 1.10 中的 Manage Memory。 > > > > Thank you~ > > Xintong Song > > > > > > On Sun, Mar 8, 2020 at 4:49 PM pkuvisdudu <[hidden email]> wrote: > > Hi all, > > > 我是Flink新人,最近在看一些flink资源管理机制的知识,有3个内存类型方面的问题想请教大家: > > > 1. > Flink的内存类型如下图1所示,其中Heap内存和NonHeap内存由JVM管理,我想问一下Direct内存是否也是由JVM管理?因为我同时也看到过图2所示的内存类型,上面标示的是JVM > Direct,但在FLIP102里看到的是属于Outside JVM,所以现在有点困惑。另外,我从相关页面上只看到了Network buffers, > Managed memory, Heap的计算方法,但不知道按照图1所示的内存类型,Direct内存和NonHeap是怎么计算分配的? > 图1 > 图2 > 2. Flink metrics里展示的内存方面的信息以Status.JVM.Memory为前缀,包含Heap, NonHeap, Direct, > Mapped四种。我测试过,这四种内存Used之和应该并不是TM真正所使用的总内存。那么TM使用的总内存还包括哪些,是在哪里用到的?(不知道是不是cut-off那部分使用的内存?)Flink > 1.10似乎对内存进行了更细致的划分和分配,但在metrics里展示的内配置和使用信息还是跟1.9一样的么? > 3. Window相关的算子会将窗口内的数据作为状态保存在内存里,等待窗口触发再进行计算。想问一下这里的状态是存在哪种类型的内存里面? > > > 祝好, > > > > > |
|
|
hi,xintong,
我是 zhisheng,留意到你在回答 Flink 1.10 中到内存分配的问题,刚好我也继续问一个我的疑问。因为我在 YadongXie <https://cwiki.apache.org/confluence/display/~vthinkxie> 发起的 FLIP-102 中关于 TaskManager UI 内存分配的展示,Non-heap 主要是由 MetaSpace 和 Overhead 组成的,如下图所示: http://zhisheng-blog.oss-cn-hangzhou.aliyuncs.com/2020-03-09-152736.png 在 FLIP-49 中看到 MetaSpace 和 Overhead 的默认配置和 fraction,看得出其实这两者加起来的值应该不会很大。 http://zhisheng-blog.oss-cn-hangzhou.aliyuncs.com/2020-03-09-153057.png 另外还从 FLIP-49 memory calculations 看到了内存的计算方式如下图所示, http://zhisheng-blog.oss-cn-hangzhou.aliyuncs.com/2020-03-09-153618.png 从上面这个图中的分配值加起来看,数值应该也不会很大,但是我自己本地 Mac 电脑起了一个 standalone 的 Flink,Non-Heap 占的比例很大,截图如下: http://zhisheng-blog.oss-cn-hangzhou.aliyuncs.com/2020-03-09-154154.png 从上面的截图中可以发现 Non-heap Max 是 1.33 GB,而整个 Heap 是 1.83 GB。说到这个 Heap 这么大,我的问题又来了,flink-conf.yaml 中 taskmanager.memory.process.size: 1568m 这个参数我没改动,了解到这个参数是表示 Total Process memory,应该该值已经是最大的内存值了,其他的加起来应该不会再超过这个值了。 种种疑问🤔️加起来就比较郁闷了,下面我总结下我的疑问,还望辛童可以有空的时候可以答疑一下,感谢🙏。 总结下我的问题: 1、Non-Heap 那个 UI 上展示的是否是 MetaSpace 和 Overhead 加起来的值? 2、为什么本地起的 Standalone Flink,为啥 UI 上展示的 Heap 会超过设置的 taskmanager.memory.process.size 的值? 3、默认 Flink 自身的配置下,启动 Flink 1.9 和 1.10,运行相同的作业他们性能之间的差距大概是什么样的?如果上生产是否可以使用默认的内存配置?会不会堆内存有点小了?这个我说下我自己简单测试了下 Flink 1.9 和 1.10 下运行同一个有状态的作业,他们的 GC 情况差别还挺大的。1.10 Young GC 次数差不多是 1.9 的两倍。 Xintong Song <[hidden email]> 于2020年3月9日周一 下午6:39写道: > > > > 图1中的Direct类型里面所包含的framework offheap、task offheap以及shuffle就是您讲的“不在 JVM > > 堆上但受到 JVM 管理的内存:Direct”么? > > 是的 > > > > 这部分内存是可以知道其使用情况并在metrics里看到的么? > > 应该是与metrics中的Direct是对应的(因为绝大多数情况我们没有使用Mapped Buffer),这里细节我记不太清楚了最好再确认下。 > > 另外,flink 1.10里将RocksDBStateBackend改为使用managed memory,不过网页上显示的是managed > > memory统一使用offheap内存,您的解答里说的是native内存,不知道是不是您说的“完全不受 JVM 管理的内存:Native”这个? > > 是的 > > 不是太清楚offheap和direct以及native的关系是怎样的 > > Flink 配置项中的 task/framework offheap,是包括了 direct 和 native > 内存算在一起的,也就是说用户不需要关心具体使用的是 direct 还是 native。 > > 最后,我在官网上看managed memory和network buffers在作业启动后会有变化 > > > 能把具体的页面链接发一下吗,可能指的是1.9以前的情况,1.10是不会变化的。1.9以前的话,TM会在进程启动并初始化之后触发一次GC,然后以GC后的空闲内存作为Heap内存重新算一遍managed、network内存应该多大。 > > Thank you~ > > Xintong Song > > > > On Mon, Mar 9, 2020 at 3:23 PM pkuvisdudu <[hidden email]> wrote: > > > 非常详细的解答,非常感谢~~ > > > > 还有一些小疑问。图1中的Direct类型里面所包含的framework offheap、task offheap以及shuffle就是您讲的“不在 > > JVM 堆上但受到 JVM 管理的内存:Direct”么?这部分内存是可以知道其使用情况并在metrics里看到的么? > > > > 另外,flink 1.10里将RocksDBStateBackend改为使用managed memory,不过网页上显示的是managed > > memory统一使用offheap内存,您的解答里说的是native内存,不知道是不是您说的“完全不受 JVM > > 管理的内存:Native”这个?不是太清楚offheap和direct以及native的关系是怎样的 > > > > 最后,我在官网上看managed memory和network > > buffers在作业启动后会有变化,但我一直看不懂是咋变化的😂,不知道这里能否解答一下 > > > > 再次感谢详细的解答~~ > > > > > > > > > > | | > > 张江 > > | > > | > > 邮箱:[hidden email] > > | > > > > 签名由 网易邮箱大师 定制 > > > > 在2020年03月09日 11:22,Xintong Song 写道: > > Hi, > > > > > > 关于你的几个问题: > > > > > > 1. 关于 JVM 的内存,堆内存(Heap Memory)的定义通常是比较清晰的,但堆外/非堆内存(Off-Heap/Non-Heap > > Memory)的定义却有很多不同的版本,这应该是导致你困惑的主要原因。让我们先抛开这些名词,本质上 Java 应用使用的内存(不包括 JVM > > 自身的开销)可以分为三类: > > JVM 堆内存:Heap > > 不在 JVM 堆上但受到 JVM 管理的内存:Direct > > 完全不受 JVM 管理的内存:Native > > Direct 内存是直接映射到 JVM 虚拟机外部的内存空间,但是其用量又受到 JVM 的管理和限制,从这个角度来讲,认为它是 JVM 内存或者非 > > JVM 内存都是讲得通的。 > > > > > > 关于 Off-Heap/Non-Heap,广义上讲只要不是 Heap 内存就可以称为 Non-Heap,但是我们经过实验发现 MXBean 的 > > Non-Heap 是不包括 Direct,而是由 Code Cache、Metaspace、Compressed Class Space > > 几个部分组成。FLIP-102 讨论的是 metrics 如何在 WebUI 上展示,Flink metrics 是通过 MXBean > > 获取的,因此图一展示的 Non-Heap 是与 MXBean 的 Non-Heap 定义的。 > > > > > > 2. Heap/Non-Heap 前面已经介绍过,而 Direct/Mapped 则同样是通过 MXBean 统计两个 Buffer Pool > > 的情况。这里的 Direct 指的是 Direct Buffer Pool 而不是 Direct Memory,这两个 Buffer Pool > 都是受 > > -XX:MaxDirectMemorySize 控制的,可以认为都是 Direct Memory 的一部分。 > > > > > > 这几个 metrics 加在一起不是 TM 的总内存,一方面是因为 Native 内存没有被算进去(也就是 Cut-off 的主要部分),因为 > > Native 是不受 JVM 管理的,MXBean 完全不知道它的使用情况。另一方面,JVM > 自身的开销也并不是都被覆盖到了,比如对于栈空间,JVM > > 只能限制每个线程的栈空间有多大,但是不能限制线程的数量,因此总的栈空间大小也是不受控制的,也没有通过 Metric 来体现。 > > > > > > 总的来说,JVM 的内存机制是非常复杂的,且并不是每一个部分都能够由用户参数控制的。Flink 1.10 > > 简化了内存模型,目的是让用户不需要去关心这其中的细节,只关注 Flink 各功能模块所需的相关内存大小即可。而目前在 1.10 中的 metric > > 是比较缺失的无法完全描述 Flink 的内存使用情况,社区提出 FLIP-102 梳理 metrics 及 UI > > 展示也正是为了解决这个问题。但即便如此,受 JVM 内存机制本身的限制,恐怕也很难做到每个部分都完全匹配到对应的 metrics 上。 > > > > > > 3. 这个应该是存在 state 里的,具体用哪种类型的内存取决于你的 State Backend > > 类型。MemoryStateBackend/FsStateBackend 用的是 Heap 内存,RocksDBStateBackend 用的是 > > Native 内存,也就是 1.10 中的 Manage Memory。 > > > > > > > > Thank you~ > > > > Xintong Song > > > > > > > > > > > > On Sun, Mar 8, 2020 at 4:49 PM pkuvisdudu <[hidden email]> wrote: > > > > Hi all, > > > > > > 我是Flink新人,最近在看一些flink资源管理机制的知识,有3个内存类型方面的问题想请教大家: > > > > > > 1. > > > Flink的内存类型如下图1所示,其中Heap内存和NonHeap内存由JVM管理,我想问一下Direct内存是否也是由JVM管理?因为我同时也看到过图2所示的内存类型,上面标示的是JVM > > Direct,但在FLIP102里看到的是属于Outside JVM,所以现在有点困惑。另外,我从相关页面上只看到了Network > buffers, > > Managed memory, Heap的计算方法,但不知道按照图1所示的内存类型,Direct内存和NonHeap是怎么计算分配的? > > 图1 > > 图2 > > 2. Flink metrics里展示的内存方面的信息以Status.JVM.Memory为前缀,包含Heap, NonHeap, Direct, > > > Mapped四种。我测试过,这四种内存Used之和应该并不是TM真正所使用的总内存。那么TM使用的总内存还包括哪些,是在哪里用到的?(不知道是不是cut-off那部分使用的内存?)Flink > > 1.10似乎对内存进行了更细致的划分和分配,但在metrics里展示的内配置和使用信息还是跟1.9一样的么? > > 3. Window相关的算子会将窗口内的数据作为状态保存在内存里,等待窗口触发再进行计算。想问一下这里的状态是存在哪种类型的内存里面? > > > > > > 祝好, > > > > > > > > > > > |
|
|
In reply to this post by Xintong Song
多谢解答。
managed memory和network buffers在作业启动后会有调整是在 https://ci.apache.org/projects/flink/flink-docs-release-1.9/ops/mem_setup.html 里看到的,是1.9版本里的。 还有两个小地方想确认一下,一是您前面说native内存是无法知道使用情况的,那么除了cut-off里的native内存,在Flink 配置项中 task/framework offheap(包括 direct 和 native内存)其中的native内存,以及1.10里managed memory使用的native 内存,是不是也无法在metrics里展示使用情况? 第二个是我看到metrics里directMemoryUsed总是和所配置的direct内存大小是一样的,不知道具体原因是啥? 再次非常感谢~ 在 2020-03-09 18:39:13,"Xintong Song" <[hidden email]> 写道: >> >> 图1中的Direct类型里面所包含的framework offheap、task offheap以及shuffle就是您讲的“不在 JVM >> 堆上但受到 JVM 管理的内存:Direct”么? > >是的 > > >> 这部分内存是可以知道其使用情况并在metrics里看到的么? > >应该是与metrics中的Direct是对应的(因为绝大多数情况我们没有使用Mapped Buffer),这里细节我记不太清楚了最好再确认下。 > >另外,flink 1.10里将RocksDBStateBackend改为使用managed memory,不过网页上显示的是managed >> memory统一使用offheap内存,您的解答里说的是native内存,不知道是不是您说的“完全不受 JVM 管理的内存:Native”这个? > >是的 > >不是太清楚offheap和direct以及native的关系是怎样的 > >Flink 配置项中的 task/framework offheap,是包括了 direct 和 native >内存算在一起的,也就是说用户不需要关心具体使用的是 direct 还是 native。 > >最后,我在官网上看managed memory和network buffers在作业启动后会有变化 > >能把具体的页面链接发一下吗,可能指的是1.9以前的情况,1.10是不会变化的。1.9以前的话,TM会在进程启动并初始化之后触发一次GC,然后以GC后的空闲内存作为Heap内存重新算一遍managed、network内存应该多大。 > >Thank you~ > >Xintong Song > > > >On Mon, Mar 9, 2020 at 3:23 PM pkuvisdudu <[hidden email]> wrote: > >> 非常详细的解答,非常感谢~~ >> >> 还有一些小疑问。图1中的Direct类型里面所包含的framework offheap、task offheap以及shuffle就是您讲的“不在 >> JVM 堆上但受到 JVM 管理的内存:Direct”么?这部分内存是可以知道其使用情况并在metrics里看到的么? >> >> 另外,flink 1.10里将RocksDBStateBackend改为使用managed memory,不过网页上显示的是managed >> memory统一使用offheap内存,您的解答里说的是native内存,不知道是不是您说的“完全不受 JVM >> 管理的内存:Native”这个?不是太清楚offheap和direct以及native的关系是怎样的 >> >> 最后,我在官网上看managed memory和network >> buffers在作业启动后会有变化,但我一直看不懂是咋变化的,不知道这里能否解答一下 >> >> 再次感谢详细的解答~~ >> >> >> >> >> | | >> 张江 >> | >> | >> 邮箱:[hidden email] >> | >> >> 签名由 网易邮箱大师 定制 >> >> 在2020年03月09日 11:22,Xintong Song 写道: >> Hi, >> >> >> 关于你的几个问题: >> >> >> 1. 关于 JVM 的内存,堆内存(Heap Memory)的定义通常是比较清晰的,但堆外/非堆内存(Off-Heap/Non-Heap >> Memory)的定义却有很多不同的版本,这应该是导致你困惑的主要原因。让我们先抛开这些名词,本质上 Java 应用使用的内存(不包括 JVM >> 自身的开销)可以分为三类: >> JVM 堆内存:Heap >> 不在 JVM 堆上但受到 JVM 管理的内存:Direct >> 完全不受 JVM 管理的内存:Native >> Direct 内存是直接映射到 JVM 虚拟机外部的内存空间,但是其用量又受到 JVM 的管理和限制,从这个角度来讲,认为它是 JVM 内存或者非 >> JVM 内存都是讲得通的。 >> >> >> 关于 Off-Heap/Non-Heap,广义上讲只要不是 Heap 内存就可以称为 Non-Heap,但是我们经过实验发现 MXBean 的 >> Non-Heap 是不包括 Direct,而是由 Code Cache、Metaspace、Compressed Class Space >> 几个部分组成。FLIP-102 讨论的是 metrics 如何在 WebUI 上展示,Flink metrics 是通过 MXBean >> 获取的,因此图一展示的 Non-Heap 是与 MXBean 的 Non-Heap 定义的。 >> >> >> 2. Heap/Non-Heap 前面已经介绍过,而 Direct/Mapped 则同样是通过 MXBean 统计两个 Buffer Pool >> 的情况。这里的 Direct 指的是 Direct Buffer Pool 而不是 Direct Memory,这两个 Buffer Pool 都是受 >> -XX:MaxDirectMemorySize 控制的,可以认为都是 Direct Memory 的一部分。 >> >> >> 这几个 metrics 加在一起不是 TM 的总内存,一方面是因为 Native 内存没有被算进去(也就是 Cut-off 的主要部分),因为 >> Native 是不受 JVM 管理的,MXBean 完全不知道它的使用情况。另一方面,JVM 自身的开销也并不是都被覆盖到了,比如对于栈空间,JVM >> 只能限制每个线程的栈空间有多大,但是不能限制线程的数量,因此总的栈空间大小也是不受控制的,也没有通过 Metric 来体现。 >> >> >> 总的来说,JVM 的内存机制是非常复杂的,且并不是每一个部分都能够由用户参数控制的。Flink 1.10 >> 简化了内存模型,目的是让用户不需要去关心这其中的细节,只关注 Flink 各功能模块所需的相关内存大小即可。而目前在 1.10 中的 metric >> 是比较缺失的无法完全描述 Flink 的内存使用情况,社区提出 FLIP-102 梳理 metrics 及 UI >> 展示也正是为了解决这个问题。但即便如此,受 JVM 内存机制本身的限制,恐怕也很难做到每个部分都完全匹配到对应的 metrics 上。 >> >> >> 3. 这个应该是存在 state 里的,具体用哪种类型的内存取决于你的 State Backend >> 类型。MemoryStateBackend/FsStateBackend 用的是 Heap 内存,RocksDBStateBackend 用的是 >> Native 内存,也就是 1.10 中的 Manage Memory。 >> >> >> >> Thank you~ >> >> Xintong Song >> >> >> >> >> >> On Sun, Mar 8, 2020 at 4:49 PM pkuvisdudu <[hidden email]> wrote: >> >> Hi all, >> >> >> 我是Flink新人,最近在看一些flink资源管理机制的知识,有3个内存类型方面的问题想请教大家: >> >> >> 1. >> Flink的内存类型如下图1所示,其中Heap内存和NonHeap内存由JVM管理,我想问一下Direct内存是否也是由JVM管理?因为我同时也看到过图2所示的内存类型,上面标示的是JVM >> Direct,但在FLIP102里看到的是属于Outside JVM,所以现在有点困惑。另外,我从相关页面上只看到了Network buffers, >> Managed memory, Heap的计算方法,但不知道按照图1所示的内存类型,Direct内存和NonHeap是怎么计算分配的? >> 图1 >> 图2 >> 2. Flink metrics里展示的内存方面的信息以Status.JVM.Memory为前缀,包含Heap, NonHeap, Direct, >> Mapped四种。我测试过,这四种内存Used之和应该并不是TM真正所使用的总内存。那么TM使用的总内存还包括哪些,是在哪里用到的?(不知道是不是cut-off那部分使用的内存?)Flink >> 1.10似乎对内存进行了更细致的划分和分配,但在metrics里展示的内配置和使用信息还是跟1.9一样的么? >> 3. Window相关的算子会将窗口内的数据作为状态保存在内存里,等待窗口触发再进行计算。想问一下这里的状态是存在哪种类型的内存里面? >> >> >> 祝好, >> >> >> >> >> |
|
|
Hi Zhisheng,
1、Non-Heap 那个 UI 上展示的是否是 MetaSpace 和 Overhead 加起来的值? 从物理含义上来说,Non-Heap 描述的内存开销是包含在 Metaspace + Overhead 里的。 > 2、为什么本地起的 Standalone Flink,为啥 UI 上展示的 Heap 会超过设置的 > taskmanager.memory.process.size 的值? 这主要是因为,我们只针对 Metaspace 设置了 JVM 的参数,对于其他 Overhead 并没有设置 JVM 的参数,也并不是所有的 Overhead 都有参数可以控制(比如栈空间)。 Non-Heap Max 是 JVM 自己决定的,所以通常会比 Flink 配置的 Metaspace + Overhead 要大。可以这样理解,Flink 将整个 TM 的内存预算划分给了不同的用途,但是并不能严格保证各部分的内存都不超用,只能是 Best Effort。其中,Managed、Network、Metaspace 是严格限制的,Off-Heap、Overhead 是不能完全严格限制的,Heap 整体是严格限制的但是 Task/Framework 之间是非严格的。 Non-Heap 这个 metric 对用户的意义不大,且容易造成用户误解。FLIP-102 目前还在讨论中,我们也在给 Yadong 提建议是否就不展示 Non-Heap了。 3、默认 Flink 自身的配置下,启动 Flink 1.9 和 > 1.10,运行相同的作业他们性能之间的差距大概是什么样的?如果上生产是否可以使用默认的内存配置?会不会堆内存有点小了?这个我说下我自己简单测试了下 > Flink 1.9 和 1.10 下运行同一个有状态的作业,他们的 GC 情况差别还挺大的。1.10 Young GC 次数差不多是 1.9 的两倍。 1.10 默认配置比起 1.9,减小了 Heap 增大了 Managed,可以参考 Memory Calculation Sheet [1] 中的 1.9/1.10 默认配置各部分内存大小对比(可以把这个表复制到自己的空间取得写权限,对各配置项的值进行修改可以直接看到各部分内存大小的变化)。至于对作业性能的影响,主要取决于作业类型(流还是批、statebackend类型等),没法一概而论。默认配置主要考虑的是用户初始尝试 Flink 的需求,如果上生产的话,通常是需要改配置的。 Hi 张江, 一是您前面说native内存是无法知道使用情况的,那么除了cut-off里的native内存,在Flink 配置项中 task/framework > offheap(包括 direct 和 native内存)其中的native内存,以及1.10里managed memory使用的native > 内存,是不是也无法在metrics里展示使用情况? Task/Framework OffHeap 也无法在 metrics 里展示。Managed Memory 理论上 Flink 自己有统计,我们也在考虑增加相应的 metrics 展示,目前的话也还是看不到的。 第二个是我看到metrics里directMemoryUsed总是和所配置的direct内存大小是一样的,不知道具体原因是啥? 要看你所说的“所配置的direct内存大小”是指什么? Thank you~ Xintong Song [1] https://docs.google.com/spreadsheets/d/1mJaMkMPfDJJ-w6nMXALYmTc4XxiV30P5U7DzgwLkSoE/edit#gid=0 On Tue, Mar 10, 2020 at 12:07 AM pkuvisdudu <[hidden email]> wrote: > 多谢解答。 > managed memory和network buffers在作业启动后会有调整是在 > https://ci.apache.org/projects/flink/flink-docs-release-1.9/ops/mem_setup.html > 里看到的,是1.9版本里的。 > > > 还有两个小地方想确认一下,一是您前面说native内存是无法知道使用情况的,那么除了cut-off里的native内存,在Flink 配置项中 > task/framework offheap(包括 direct 和 native内存)其中的native内存,以及1.10里managed > memory使用的native 内存,是不是也无法在metrics里展示使用情况? > 第二个是我看到metrics里directMemoryUsed总是和所配置的direct内存大小是一样的,不知道具体原因是啥? > > > 再次非常感谢~ > > > > > > > > > > > > 在 2020-03-09 18:39:13,"Xintong Song" <[hidden email]> 写道: > >> > >> 图1中的Direct类型里面所包含的framework offheap、task offheap以及shuffle就是您讲的“不在 JVM > >> 堆上但受到 JVM 管理的内存:Direct”么? > > > >是的 > > > > > >> 这部分内存是可以知道其使用情况并在metrics里看到的么? > > > >应该是与metrics中的Direct是对应的(因为绝大多数情况我们没有使用Mapped Buffer),这里细节我记不太清楚了最好再确认下。 > > > >另外,flink 1.10里将RocksDBStateBackend改为使用managed memory,不过网页上显示的是managed > >> memory统一使用offheap内存,您的解答里说的是native内存,不知道是不是您说的“完全不受 JVM 管理的内存:Native”这个? > > > >是的 > > > >不是太清楚offheap和direct以及native的关系是怎样的 > > > >Flink 配置项中的 task/framework offheap,是包括了 direct 和 native > >内存算在一起的,也就是说用户不需要关心具体使用的是 direct 还是 native。 > > > >最后,我在官网上看managed memory和network buffers在作业启动后会有变化 > > > > >能把具体的页面链接发一下吗,可能指的是1.9以前的情况,1.10是不会变化的。1.9以前的话,TM会在进程启动并初始化之后触发一次GC,然后以GC后的空闲内存作为Heap内存重新算一遍managed、network内存应该多大。 > > > >Thank you~ > > > >Xintong Song > > > > > > > >On Mon, Mar 9, 2020 at 3:23 PM pkuvisdudu <[hidden email]> wrote: > > > >> 非常详细的解答,非常感谢~~ > >> > >> 还有一些小疑问。图1中的Direct类型里面所包含的framework offheap、task > offheap以及shuffle就是您讲的“不在 > >> JVM 堆上但受到 JVM 管理的内存:Direct”么?这部分内存是可以知道其使用情况并在metrics里看到的么? > >> > >> 另外,flink 1.10里将RocksDBStateBackend改为使用managed memory,不过网页上显示的是managed > >> memory统一使用offheap内存,您的解答里说的是native内存,不知道是不是您说的“完全不受 JVM > >> 管理的内存:Native”这个?不是太清楚offheap和direct以及native的关系是怎样的 > >> > >> 最后,我在官网上看managed memory和network > >> buffers在作业启动后会有变化,但我一直看不懂是咋变化的,不知道这里能否解答一下 > >> > >> 再次感谢详细的解答~~ > >> > >> > >> > >> > >> | | > >> 张江 > >> | > >> | > >> 邮箱:[hidden email] > >> | > >> > >> 签名由 网易邮箱大师 定制 > >> > >> 在2020年03月09日 11:22,Xintong Song 写道: > >> Hi, > >> > >> > >> 关于你的几个问题: > >> > >> > >> 1. 关于 JVM 的内存,堆内存(Heap Memory)的定义通常是比较清晰的,但堆外/非堆内存(Off-Heap/Non-Heap > >> Memory)的定义却有很多不同的版本,这应该是导致你困惑的主要原因。让我们先抛开这些名词,本质上 Java 应用使用的内存(不包括 JVM > >> 自身的开销)可以分为三类: > >> JVM 堆内存:Heap > >> 不在 JVM 堆上但受到 JVM 管理的内存:Direct > >> 完全不受 JVM 管理的内存:Native > >> Direct 内存是直接映射到 JVM 虚拟机外部的内存空间,但是其用量又受到 JVM 的管理和限制,从这个角度来讲,认为它是 JVM > 内存或者非 > >> JVM 内存都是讲得通的。 > >> > >> > >> 关于 Off-Heap/Non-Heap,广义上讲只要不是 Heap 内存就可以称为 Non-Heap,但是我们经过实验发现 MXBean 的 > >> Non-Heap 是不包括 Direct,而是由 Code Cache、Metaspace、Compressed Class Space > >> 几个部分组成。FLIP-102 讨论的是 metrics 如何在 WebUI 上展示,Flink metrics 是通过 MXBean > >> 获取的,因此图一展示的 Non-Heap 是与 MXBean 的 Non-Heap 定义的。 > >> > >> > >> 2. Heap/Non-Heap 前面已经介绍过,而 Direct/Mapped 则同样是通过 MXBean 统计两个 Buffer Pool > >> 的情况。这里的 Direct 指的是 Direct Buffer Pool 而不是 Direct Memory,这两个 Buffer Pool > 都是受 > >> -XX:MaxDirectMemorySize 控制的,可以认为都是 Direct Memory 的一部分。 > >> > >> > >> 这几个 metrics 加在一起不是 TM 的总内存,一方面是因为 Native 内存没有被算进去(也就是 Cut-off 的主要部分),因为 > >> Native 是不受 JVM 管理的,MXBean 完全不知道它的使用情况。另一方面,JVM > 自身的开销也并不是都被覆盖到了,比如对于栈空间,JVM > >> 只能限制每个线程的栈空间有多大,但是不能限制线程的数量,因此总的栈空间大小也是不受控制的,也没有通过 Metric 来体现。 > >> > >> > >> 总的来说,JVM 的内存机制是非常复杂的,且并不是每一个部分都能够由用户参数控制的。Flink 1.10 > >> 简化了内存模型,目的是让用户不需要去关心这其中的细节,只关注 Flink 各功能模块所需的相关内存大小即可。而目前在 1.10 中的 > metric > >> 是比较缺失的无法完全描述 Flink 的内存使用情况,社区提出 FLIP-102 梳理 metrics 及 UI > >> 展示也正是为了解决这个问题。但即便如此,受 JVM 内存机制本身的限制,恐怕也很难做到每个部分都完全匹配到对应的 metrics 上。 > >> > >> > >> 3. 这个应该是存在 state 里的,具体用哪种类型的内存取决于你的 State Backend > >> 类型。MemoryStateBackend/FsStateBackend 用的是 Heap 内存,RocksDBStateBackend 用的是 > >> Native 内存,也就是 1.10 中的 Manage Memory。 > >> > >> > >> > >> Thank you~ > >> > >> Xintong Song > >> > >> > >> > >> > >> > >> On Sun, Mar 8, 2020 at 4:49 PM pkuvisdudu <[hidden email]> > wrote: > >> > >> Hi all, > >> > >> > >> 我是Flink新人,最近在看一些flink资源管理机制的知识,有3个内存类型方面的问题想请教大家: > >> > >> > >> 1. > >> > Flink的内存类型如下图1所示,其中Heap内存和NonHeap内存由JVM管理,我想问一下Direct内存是否也是由JVM管理?因为我同时也看到过图2所示的内存类型,上面标示的是JVM > >> Direct,但在FLIP102里看到的是属于Outside JVM,所以现在有点困惑。另外,我从相关页面上只看到了Network > buffers, > >> Managed memory, Heap的计算方法,但不知道按照图1所示的内存类型,Direct内存和NonHeap是怎么计算分配的? > >> 图1 > >> 图2 > >> 2. Flink metrics里展示的内存方面的信息以Status.JVM.Memory为前缀,包含Heap, NonHeap, > Direct, > >> > Mapped四种。我测试过,这四种内存Used之和应该并不是TM真正所使用的总内存。那么TM使用的总内存还包括哪些,是在哪里用到的?(不知道是不是cut-off那部分使用的内存?)Flink > >> 1.10似乎对内存进行了更细致的划分和分配,但在metrics里展示的内配置和使用信息还是跟1.9一样的么? > >> 3. Window相关的算子会将窗口内的数据作为状态保存在内存里,等待窗口触发再进行计算。想问一下这里的状态是存在哪种类型的内存里面? > >> > >> > >> 祝好, > >> > >> > >> > >> > >> > |
|
|
hi,xintong,感谢耐心且专业的回答👍
Xintong Song <[hidden email]> 于2020年3月10日周二 上午10:04写道: > Hi Zhisheng, > > 1、Non-Heap 那个 UI 上展示的是否是 MetaSpace 和 Overhead 加起来的值? > > > 从物理含义上来说,Non-Heap 描述的内存开销是包含在 Metaspace + Overhead 里的。 > > > > 2、为什么本地起的 Standalone Flink,为啥 UI 上展示的 Heap 会超过设置的 > > taskmanager.memory.process.size 的值? > > > 这主要是因为,我们只针对 Metaspace 设置了 JVM 的参数,对于其他 Overhead 并没有设置 JVM 的参数,也并不是所有的 > Overhead 都有参数可以控制(比如栈空间)。 > > Non-Heap Max 是 JVM 自己决定的,所以通常会比 Flink 配置的 Metaspace + Overhead > 要大。可以这样理解,Flink 将整个 TM 的内存预算划分给了不同的用途,但是并不能严格保证各部分的内存都不超用,只能是 Best > Effort。其中,Managed、Network、Metaspace 是严格限制的,Off-Heap、Overhead > 是不能完全严格限制的,Heap 整体是严格限制的但是 Task/Framework 之间是非严格的。 > > Non-Heap 这个 metric 对用户的意义不大,且容易造成用户误解。FLIP-102 目前还在讨论中,我们也在给 Yadong > 提建议是否就不展示 Non-Heap了。 > > 3、默认 Flink 自身的配置下,启动 Flink 1.9 和 > > 1.10,运行相同的作业他们性能之间的差距大概是什么样的?如果上生产是否可以使用默认的内存配置?会不会堆内存有点小了?这个我说下我自己简单测试了下 > > Flink 1.9 和 1.10 下运行同一个有状态的作业,他们的 GC 情况差别还挺大的。1.10 Young GC 次数差不多是 1.9 > 的两倍。 > > > 1.10 默认配置比起 1.9,减小了 Heap 增大了 Managed,可以参考 Memory Calculation Sheet [1] 中的 > 1.9/1.10 > > 默认配置各部分内存大小对比(可以把这个表复制到自己的空间取得写权限,对各配置项的值进行修改可以直接看到各部分内存大小的变化)。至于对作业性能的影响,主要取决于作业类型(流还是批、statebackend类型等),没法一概而论。默认配置主要考虑的是用户初始尝试 > Flink 的需求,如果上生产的话,通常是需要改配置的。 > > > Hi 张江, > > > 一是您前面说native内存是无法知道使用情况的,那么除了cut-off里的native内存,在Flink 配置项中 task/framework > > offheap(包括 direct 和 native内存)其中的native内存,以及1.10里managed memory使用的native > > 内存,是不是也无法在metrics里展示使用情况? > > > Task/Framework OffHeap 也无法在 metrics 里展示。Managed Memory 理论上 Flink > 自己有统计,我们也在考虑增加相应的 metrics 展示,目前的话也还是看不到的。 > > > 第二个是我看到metrics里directMemoryUsed总是和所配置的direct内存大小是一样的,不知道具体原因是啥? > > > 要看你所说的“所配置的direct内存大小”是指什么? > > > Thank you~ > > Xintong Song > > > [1] > > https://docs.google.com/spreadsheets/d/1mJaMkMPfDJJ-w6nMXALYmTc4XxiV30P5U7DzgwLkSoE/edit#gid=0 > > On Tue, Mar 10, 2020 at 12:07 AM pkuvisdudu <[hidden email]> wrote: > > > 多谢解答。 > > managed memory和network buffers在作业启动后会有调整是在 > > > https://ci.apache.org/projects/flink/flink-docs-release-1.9/ops/mem_setup.html > > 里看到的,是1.9版本里的。 > > > > > > 还有两个小地方想确认一下,一是您前面说native内存是无法知道使用情况的,那么除了cut-off里的native内存,在Flink 配置项中 > > task/framework offheap(包括 direct 和 native内存)其中的native内存,以及1.10里managed > > memory使用的native 内存,是不是也无法在metrics里展示使用情况? > > 第二个是我看到metrics里directMemoryUsed总是和所配置的direct内存大小是一样的,不知道具体原因是啥? > > > > > > 再次非常感谢~ > > > > > > > > > > > > > > > > > > > > > > > > 在 2020-03-09 18:39:13,"Xintong Song" <[hidden email]> 写道: > > >> > > >> 图1中的Direct类型里面所包含的framework offheap、task offheap以及shuffle就是您讲的“不在 JVM > > >> 堆上但受到 JVM 管理的内存:Direct”么? > > > > > >是的 > > > > > > > > >> 这部分内存是可以知道其使用情况并在metrics里看到的么? > > > > > >应该是与metrics中的Direct是对应的(因为绝大多数情况我们没有使用Mapped Buffer),这里细节我记不太清楚了最好再确认下。 > > > > > >另外,flink 1.10里将RocksDBStateBackend改为使用managed memory,不过网页上显示的是managed > > >> memory统一使用offheap内存,您的解答里说的是native内存,不知道是不是您说的“完全不受 JVM > 管理的内存:Native”这个? > > > > > >是的 > > > > > >不是太清楚offheap和direct以及native的关系是怎样的 > > > > > >Flink 配置项中的 task/framework offheap,是包括了 direct 和 native > > >内存算在一起的,也就是说用户不需要关心具体使用的是 direct 还是 native。 > > > > > >最后,我在官网上看managed memory和network buffers在作业启动后会有变化 > > > > > > > > >能把具体的页面链接发一下吗,可能指的是1.9以前的情况,1.10是不会变化的。1.9以前的话,TM会在进程启动并初始化之后触发一次GC,然后以GC后的空闲内存作为Heap内存重新算一遍managed、network内存应该多大。 > > > > > >Thank you~ > > > > > >Xintong Song > > > > > > > > > > > >On Mon, Mar 9, 2020 at 3:23 PM pkuvisdudu <[hidden email]> > wrote: > > > > > >> 非常详细的解答,非常感谢~~ > > >> > > >> 还有一些小疑问。图1中的Direct类型里面所包含的framework offheap、task > > offheap以及shuffle就是您讲的“不在 > > >> JVM 堆上但受到 JVM 管理的内存:Direct”么?这部分内存是可以知道其使用情况并在metrics里看到的么? > > >> > > >> 另外,flink 1.10里将RocksDBStateBackend改为使用managed memory,不过网页上显示的是managed > > >> memory统一使用offheap内存,您的解答里说的是native内存,不知道是不是您说的“完全不受 JVM > > >> 管理的内存:Native”这个?不是太清楚offheap和direct以及native的关系是怎样的 > > >> > > >> 最后,我在官网上看managed memory和network > > >> buffers在作业启动后会有变化,但我一直看不懂是咋变化的,不知道这里能否解答一下 > > >> > > >> 再次感谢详细的解答~~ > > >> > > >> > > >> > > >> > > >> | | > > >> 张江 > > >> | > > >> | > > >> 邮箱:[hidden email] > > >> | > > >> > > >> 签名由 网易邮箱大师 定制 > > >> > > >> 在2020年03月09日 11:22,Xintong Song 写道: > > >> Hi, > > >> > > >> > > >> 关于你的几个问题: > > >> > > >> > > >> 1. 关于 JVM 的内存,堆内存(Heap Memory)的定义通常是比较清晰的,但堆外/非堆内存(Off-Heap/Non-Heap > > >> Memory)的定义却有很多不同的版本,这应该是导致你困惑的主要原因。让我们先抛开这些名词,本质上 Java 应用使用的内存(不包括 JVM > > >> 自身的开销)可以分为三类: > > >> JVM 堆内存:Heap > > >> 不在 JVM 堆上但受到 JVM 管理的内存:Direct > > >> 完全不受 JVM 管理的内存:Native > > >> Direct 内存是直接映射到 JVM 虚拟机外部的内存空间,但是其用量又受到 JVM 的管理和限制,从这个角度来讲,认为它是 JVM > > 内存或者非 > > >> JVM 内存都是讲得通的。 > > >> > > >> > > >> 关于 Off-Heap/Non-Heap,广义上讲只要不是 Heap 内存就可以称为 Non-Heap,但是我们经过实验发现 MXBean > 的 > > >> Non-Heap 是不包括 Direct,而是由 Code Cache、Metaspace、Compressed Class Space > > >> 几个部分组成。FLIP-102 讨论的是 metrics 如何在 WebUI 上展示,Flink metrics 是通过 MXBean > > >> 获取的,因此图一展示的 Non-Heap 是与 MXBean 的 Non-Heap 定义的。 > > >> > > >> > > >> 2. Heap/Non-Heap 前面已经介绍过,而 Direct/Mapped 则同样是通过 MXBean 统计两个 Buffer > Pool > > >> 的情况。这里的 Direct 指的是 Direct Buffer Pool 而不是 Direct Memory,这两个 Buffer > Pool > > 都是受 > > >> -XX:MaxDirectMemorySize 控制的,可以认为都是 Direct Memory 的一部分。 > > >> > > >> > > >> 这几个 metrics 加在一起不是 TM 的总内存,一方面是因为 Native 内存没有被算进去(也就是 Cut-off > 的主要部分),因为 > > >> Native 是不受 JVM 管理的,MXBean 完全不知道它的使用情况。另一方面,JVM > > 自身的开销也并不是都被覆盖到了,比如对于栈空间,JVM > > >> 只能限制每个线程的栈空间有多大,但是不能限制线程的数量,因此总的栈空间大小也是不受控制的,也没有通过 Metric 来体现。 > > >> > > >> > > >> 总的来说,JVM 的内存机制是非常复杂的,且并不是每一个部分都能够由用户参数控制的。Flink 1.10 > > >> 简化了内存模型,目的是让用户不需要去关心这其中的细节,只关注 Flink 各功能模块所需的相关内存大小即可。而目前在 1.10 中的 > > metric > > >> 是比较缺失的无法完全描述 Flink 的内存使用情况,社区提出 FLIP-102 梳理 metrics 及 UI > > >> 展示也正是为了解决这个问题。但即便如此,受 JVM 内存机制本身的限制,恐怕也很难做到每个部分都完全匹配到对应的 metrics 上。 > > >> > > >> > > >> 3. 这个应该是存在 state 里的,具体用哪种类型的内存取决于你的 State Backend > > >> 类型。MemoryStateBackend/FsStateBackend 用的是 Heap 内存,RocksDBStateBackend > 用的是 > > >> Native 内存,也就是 1.10 中的 Manage Memory。 > > >> > > >> > > >> > > >> Thank you~ > > >> > > >> Xintong Song > > >> > > >> > > >> > > >> > > >> > > >> On Sun, Mar 8, 2020 at 4:49 PM pkuvisdudu <[hidden email]> > > wrote: > > >> > > >> Hi all, > > >> > > >> > > >> 我是Flink新人,最近在看一些flink资源管理机制的知识,有3个内存类型方面的问题想请教大家: > > >> > > >> > > >> 1. > > >> > > > Flink的内存类型如下图1所示,其中Heap内存和NonHeap内存由JVM管理,我想问一下Direct内存是否也是由JVM管理?因为我同时也看到过图2所示的内存类型,上面标示的是JVM > > >> Direct,但在FLIP102里看到的是属于Outside JVM,所以现在有点困惑。另外,我从相关页面上只看到了Network > > buffers, > > >> Managed memory, Heap的计算方法,但不知道按照图1所示的内存类型,Direct内存和NonHeap是怎么计算分配的? > > >> 图1 > > >> 图2 > > >> 2. Flink metrics里展示的内存方面的信息以Status.JVM.Memory为前缀,包含Heap, NonHeap, > > Direct, > > >> > > > Mapped四种。我测试过,这四种内存Used之和应该并不是TM真正所使用的总内存。那么TM使用的总内存还包括哪些,是在哪里用到的?(不知道是不是cut-off那部分使用的内存?)Flink > > >> 1.10似乎对内存进行了更细致的划分和分配,但在metrics里展示的内配置和使用信息还是跟1.9一样的么? > > >> 3. Window相关的算子会将窗口内的数据作为状态保存在内存里,等待窗口触发再进行计算。想问一下这里的状态是存在哪种类型的内存里面? > > >> > > >> > > >> 祝好, > > >> > > >> > > >> > > >> > > >> > > > |
|
|
多谢解答。
关于“第二个是我看到metrics里directMemoryUsed总是和所配置的direct内存大小是一样的,不知道具体原因是啥?” 这里的“所配置的direct内存”,是指按照task.manager.network.memory.fraction计算得到的network memory大小。我想是不是这部分内存按照memory segment全部预分配了,所有metrics里显示的是全部是被Used了? | | 张江 | | 邮箱:[hidden email] | 签名由 网易邮箱大师 定制 在2020年03月10日 10:16,zhisheng 写道: hi,xintong,感谢耐心且专业的回答👍 Xintong Song <[hidden email]> 于2020年3月10日周二 上午10:04写道: > Hi Zhisheng, > > 1、Non-Heap 那个 UI 上展示的是否是 MetaSpace 和 Overhead 加起来的值? > > > 从物理含义上来说,Non-Heap 描述的内存开销是包含在 Metaspace + Overhead 里的。 > > > > 2、为什么本地起的 Standalone Flink,为啥 UI 上展示的 Heap 会超过设置的 > > taskmanager.memory.process.size 的值? > > > 这主要是因为,我们只针对 Metaspace 设置了 JVM 的参数,对于其他 Overhead 并没有设置 JVM 的参数,也并不是所有的 > Overhead 都有参数可以控制(比如栈空间)。 > > Non-Heap Max 是 JVM 自己决定的,所以通常会比 Flink 配置的 Metaspace + Overhead > 要大。可以这样理解,Flink 将整个 TM 的内存预算划分给了不同的用途,但是并不能严格保证各部分的内存都不超用,只能是 Best > Effort。其中,Managed、Network、Metaspace 是严格限制的,Off-Heap、Overhead > 是不能完全严格限制的,Heap 整体是严格限制的但是 Task/Framework 之间是非严格的。 > > Non-Heap 这个 metric 对用户的意义不大,且容易造成用户误解。FLIP-102 目前还在讨论中,我们也在给 Yadong > 提建议是否就不展示 Non-Heap了。 > > 3、默认 Flink 自身的配置下,启动 Flink 1.9 和 > > 1.10,运行相同的作业他们性能之间的差距大概是什么样的?如果上生产是否可以使用默认的内存配置?会不会堆内存有点小了?这个我说下我自己简单测试了下 > > Flink 1.9 和 1.10 下运行同一个有状态的作业,他们的 GC 情况差别还挺大的。1.10 Young GC 次数差不多是 1.9 > 的两倍。 > > > 1.10 默认配置比起 1.9,减小了 Heap 增大了 Managed,可以参考 Memory Calculation Sheet [1] 中的 > 1.9/1.10 > > 默认配置各部分内存大小对比(可以把这个表复制到自己的空间取得写权限,对各配置项的值进行修改可以直接看到各部分内存大小的变化)。至于对作业性能的影响,主要取决于作业类型(流还是批、statebackend类型等),没法一概而论。默认配置主要考虑的是用户初始尝试 > Flink 的需求,如果上生产的话,通常是需要改配置的。 > > > Hi 张江, > > > 一是您前面说native内存是无法知道使用情况的,那么除了cut-off里的native内存,在Flink 配置项中 task/framework > > offheap(包括 direct 和 native内存)其中的native内存,以及1.10里managed memory使用的native > > 内存,是不是也无法在metrics里展示使用情况? > > > Task/Framework OffHeap 也无法在 metrics 里展示。Managed Memory 理论上 Flink > 自己有统计,我们也在考虑增加相应的 metrics 展示,目前的话也还是看不到的。 > > > 第二个是我看到metrics里directMemoryUsed总是和所配置的direct内存大小是一样的,不知道具体原因是啥? > > > 要看你所说的“所配置的direct内存大小”是指什么? > > > Thank you~ > > Xintong Song > > > [1] > > https://docs.google.com/spreadsheets/d/1mJaMkMPfDJJ-w6nMXALYmTc4XxiV30P5U7DzgwLkSoE/edit#gid=0 > > On Tue, Mar 10, 2020 at 12:07 AM pkuvisdudu <[hidden email]> wrote: > > > 多谢解答。 > > managed memory和network buffers在作业启动后会有调整是在 > > > https://ci.apache.org/projects/flink/flink-docs-release-1.9/ops/mem_setup.html > > 里看到的,是1.9版本里的。 > > > > > > 还有两个小地方想确认一下,一是您前面说native内存是无法知道使用情况的,那么除了cut-off里的native内存,在Flink 配置项中 > > task/framework offheap(包括 direct 和 native内存)其中的native内存,以及1.10里managed > > memory使用的native 内存,是不是也无法在metrics里展示使用情况? > > 第二个是我看到metrics里directMemoryUsed总是和所配置的direct内存大小是一样的,不知道具体原因是啥? > > > > > > 再次非常感谢~ > > > > > > > > > > > > > > > > > > > > > > > > 在 2020-03-09 18:39:13,"Xintong Song" <[hidden email]> 写道: > > >> > > >> 图1中的Direct类型里面所包含的framework offheap、task offheap以及shuffle就是您讲的“不在 JVM > > >> 堆上但受到 JVM 管理的内存:Direct”么? > > > > > >是的 > > > > > > > > >> 这部分内存是可以知道其使用情况并在metrics里看到的么? > > > > > >应该是与metrics中的Direct是对应的(因为绝大多数情况我们没有使用Mapped Buffer),这里细节我记不太清楚了最好再确认下。 > > > > > >另外,flink 1.10里将RocksDBStateBackend改为使用managed memory,不过网页上显示的是managed > > >> memory统一使用offheap内存,您的解答里说的是native内存,不知道是不是您说的“完全不受 JVM > 管理的内存:Native”这个? > > > > > >是的 > > > > > >不是太清楚offheap和direct以及native的关系是怎样的 > > > > > >Flink 配置项中的 task/framework offheap,是包括了 direct 和 native > > >内存算在一起的,也就是说用户不需要关心具体使用的是 direct 还是 native。 > > > > > >最后,我在官网上看managed memory和network buffers在作业启动后会有变化 > > > > > > > > >能把具体的页面链接发一下吗,可能指的是1.9以前的情况,1.10是不会变化的。1.9以前的话,TM会在进程启动并初始化之后触发一次GC,然后以GC后的空闲内存作为Heap内存重新算一遍managed、network内存应该多大。 > > > > > >Thank you~ > > > > > >Xintong Song > > > > > > > > > > > >On Mon, Mar 9, 2020 at 3:23 PM pkuvisdudu <[hidden email]> > wrote: > > > > > >> 非常详细的解答,非常感谢~~ > > >> > > >> 还有一些小疑问。图1中的Direct类型里面所包含的framework offheap、task > > offheap以及shuffle就是您讲的“不在 > > >> JVM 堆上但受到 JVM 管理的内存:Direct”么?这部分内存是可以知道其使用情况并在metrics里看到的么? > > >> > > >> 另外,flink 1.10里将RocksDBStateBackend改为使用managed memory,不过网页上显示的是managed > > >> memory统一使用offheap内存,您的解答里说的是native内存,不知道是不是您说的“完全不受 JVM > > >> 管理的内存:Native”这个?不是太清楚offheap和direct以及native的关系是怎样的 > > >> > > >> 最后,我在官网上看managed memory和network > > >> buffers在作业启动后会有变化,但我一直看不懂是咋变化的,不知道这里能否解答一下 > > >> > > >> 再次感谢详细的解答~~ > > >> > > >> > > >> > > >> > > >> | | > > >> 张江 > > >> | > > >> | > > >> 邮箱:[hidden email] > > >> | > > >> > > >> 签名由 网易邮箱大师 定制 > > >> > > >> 在2020年03月09日 11:22,Xintong Song 写道: > > >> Hi, > > >> > > >> > > >> 关于你的几个问题: > > >> > > >> > > >> 1. 关于 JVM 的内存,堆内存(Heap Memory)的定义通常是比较清晰的,但堆外/非堆内存(Off-Heap/Non-Heap > > >> Memory)的定义却有很多不同的版本,这应该是导致你困惑的主要原因。让我们先抛开这些名词,本质上 Java 应用使用的内存(不包括 JVM > > >> 自身的开销)可以分为三类: > > >> JVM 堆内存:Heap > > >> 不在 JVM 堆上但受到 JVM 管理的内存:Direct > > >> 完全不受 JVM 管理的内存:Native > > >> Direct 内存是直接映射到 JVM 虚拟机外部的内存空间,但是其用量又受到 JVM 的管理和限制,从这个角度来讲,认为它是 JVM > > 内存或者非 > > >> JVM 内存都是讲得通的。 > > >> > > >> > > >> 关于 Off-Heap/Non-Heap,广义上讲只要不是 Heap 内存就可以称为 Non-Heap,但是我们经过实验发现 MXBean > 的 > > >> Non-Heap 是不包括 Direct,而是由 Code Cache、Metaspace、Compressed Class Space > > >> 几个部分组成。FLIP-102 讨论的是 metrics 如何在 WebUI 上展示,Flink metrics 是通过 MXBean > > >> 获取的,因此图一展示的 Non-Heap 是与 MXBean 的 Non-Heap 定义的。 > > >> > > >> > > >> 2. Heap/Non-Heap 前面已经介绍过,而 Direct/Mapped 则同样是通过 MXBean 统计两个 Buffer > Pool > > >> 的情况。这里的 Direct 指的是 Direct Buffer Pool 而不是 Direct Memory,这两个 Buffer > Pool > > 都是受 > > >> -XX:MaxDirectMemorySize 控制的,可以认为都是 Direct Memory 的一部分。 > > >> > > >> > > >> 这几个 metrics 加在一起不是 TM 的总内存,一方面是因为 Native 内存没有被算进去(也就是 Cut-off > 的主要部分),因为 > > >> Native 是不受 JVM 管理的,MXBean 完全不知道它的使用情况。另一方面,JVM > > 自身的开销也并不是都被覆盖到了,比如对于栈空间,JVM > > >> 只能限制每个线程的栈空间有多大,但是不能限制线程的数量,因此总的栈空间大小也是不受控制的,也没有通过 Metric 来体现。 > > >> > > >> > > >> 总的来说,JVM 的内存机制是非常复杂的,且并不是每一个部分都能够由用户参数控制的。Flink 1.10 > > >> 简化了内存模型,目的是让用户不需要去关心这其中的细节,只关注 Flink 各功能模块所需的相关内存大小即可。而目前在 1.10 中的 > > metric > > >> 是比较缺失的无法完全描述 Flink 的内存使用情况,社区提出 FLIP-102 梳理 metrics 及 UI > > >> 展示也正是为了解决这个问题。但即便如此,受 JVM 内存机制本身的限制,恐怕也很难做到每个部分都完全匹配到对应的 metrics 上。 > > >> > > >> > > >> 3. 这个应该是存在 state 里的,具体用哪种类型的内存取决于你的 State Backend > > >> 类型。MemoryStateBackend/FsStateBackend 用的是 Heap 内存,RocksDBStateBackend > 用的是 > > >> Native 内存,也就是 1.10 中的 Manage Memory。 > > >> > > >> > > >> > > >> Thank you~ > > >> > > >> Xintong Song > > >> > > >> > > >> > > >> > > >> > > >> On Sun, Mar 8, 2020 at 4:49 PM pkuvisdudu <[hidden email]> > > wrote: > > >> > > >> Hi all, > > >> > > >> > > >> 我是Flink新人,最近在看一些flink资源管理机制的知识,有3个内存类型方面的问题想请教大家: > > >> > > >> > > >> 1. > > >> > > > Flink的内存类型如下图1所示,其中Heap内存和NonHeap内存由JVM管理,我想问一下Direct内存是否也是由JVM管理?因为我同时也看到过图2所示的内存类型,上面标示的是JVM > > >> Direct,但在FLIP102里看到的是属于Outside JVM,所以现在有点困惑。另外,我从相关页面上只看到了Network > > buffers, > > >> Managed memory, Heap的计算方法,但不知道按照图1所示的内存类型,Direct内存和NonHeap是怎么计算分配的? > > >> 图1 > > >> 图2 > > >> 2. Flink metrics里展示的内存方面的信息以Status.JVM.Memory为前缀,包含Heap, NonHeap, > > Direct, > > >> > > > Mapped四种。我测试过,这四种内存Used之和应该并不是TM真正所使用的总内存。那么TM使用的总内存还包括哪些,是在哪里用到的?(不知道是不是cut-off那部分使用的内存?)Flink > > >> 1.10似乎对内存进行了更细致的划分和分配,但在metrics里展示的内配置和使用信息还是跟1.9一样的么? > > >> 3. Window相关的算子会将窗口内的数据作为状态保存在内存里,等待窗口触发再进行计算。想问一下这里的状态是存在哪种类型的内存里面? > > >> > > >> > > >> 祝好, > > >> > > >> > > >> > > >> > > >> > > > |
|
|
>
> 这里的“所配置的direct内存”,是指按照task.manager.network.memory.fraction计算得到的network > memory大小。我想是不是这部分内存按照memory segment全部预分配了,所有metrics里显示的是全部是被Used了? 是的,Network Buffer Pool 是在 TM 初始化时预申请好的。在所有内存类型中,只有 Network Memory 是预申请的。Managed Memory 1.9 以前是有一个配置可以预申请(默认不开),1.10 起不再支持预申请。 Thank you~ Xintong Song On Tue, Mar 10, 2020 at 10:30 AM pkuvisdudu <[hidden email]> wrote: > 多谢解答。 > 关于“第二个是我看到metrics里directMemoryUsed总是和所配置的direct内存大小是一样的,不知道具体原因是啥?” > 这里的“所配置的direct内存”,是指按照task.manager.network.memory.fraction计算得到的network > memory大小。我想是不是这部分内存按照memory segment全部预分配了,所有metrics里显示的是全部是被Used了? > > > > > | | > 张江 > | > | > 邮箱:[hidden email] > | > > 签名由 网易邮箱大师 定制 > > 在2020年03月10日 10:16,zhisheng 写道: > hi,xintong,感谢耐心且专业的回答👍 > > Xintong Song <[hidden email]> 于2020年3月10日周二 上午10:04写道: > > > Hi Zhisheng, > > > > 1、Non-Heap 那个 UI 上展示的是否是 MetaSpace 和 Overhead 加起来的值? > > > > > > 从物理含义上来说,Non-Heap 描述的内存开销是包含在 Metaspace + Overhead 里的。 > > > > > > > 2、为什么本地起的 Standalone Flink,为啥 UI 上展示的 Heap 会超过设置的 > > > taskmanager.memory.process.size 的值? > > > > > > 这主要是因为,我们只针对 Metaspace 设置了 JVM 的参数,对于其他 Overhead 并没有设置 JVM 的参数,也并不是所有的 > > Overhead 都有参数可以控制(比如栈空间)。 > > > > Non-Heap Max 是 JVM 自己决定的,所以通常会比 Flink 配置的 Metaspace + Overhead > > 要大。可以这样理解,Flink 将整个 TM 的内存预算划分给了不同的用途,但是并不能严格保证各部分的内存都不超用,只能是 Best > > Effort。其中,Managed、Network、Metaspace 是严格限制的,Off-Heap、Overhead > > 是不能完全严格限制的,Heap 整体是严格限制的但是 Task/Framework 之间是非严格的。 > > > > Non-Heap 这个 metric 对用户的意义不大,且容易造成用户误解。FLIP-102 目前还在讨论中,我们也在给 Yadong > > 提建议是否就不展示 Non-Heap了。 > > > > 3、默认 Flink 自身的配置下,启动 Flink 1.9 和 > > > > 1.10,运行相同的作业他们性能之间的差距大概是什么样的?如果上生产是否可以使用默认的内存配置?会不会堆内存有点小了?这个我说下我自己简单测试了下 > > > Flink 1.9 和 1.10 下运行同一个有状态的作业,他们的 GC 情况差别还挺大的。1.10 Young GC 次数差不多是 1.9 > > 的两倍。 > > > > > > 1.10 默认配置比起 1.9,减小了 Heap 增大了 Managed,可以参考 Memory Calculation Sheet [1] 中的 > > 1.9/1.10 > > > > > 默认配置各部分内存大小对比(可以把这个表复制到自己的空间取得写权限,对各配置项的值进行修改可以直接看到各部分内存大小的变化)。至于对作业性能的影响,主要取决于作业类型(流还是批、statebackend类型等),没法一概而论。默认配置主要考虑的是用户初始尝试 > > Flink 的需求,如果上生产的话,通常是需要改配置的。 > > > > > > Hi 张江, > > > > > > 一是您前面说native内存是无法知道使用情况的,那么除了cut-off里的native内存,在Flink 配置项中 task/framework > > > offheap(包括 direct 和 native内存)其中的native内存,以及1.10里managed memory使用的native > > > 内存,是不是也无法在metrics里展示使用情况? > > > > > > Task/Framework OffHeap 也无法在 metrics 里展示。Managed Memory 理论上 Flink > > 自己有统计,我们也在考虑增加相应的 metrics 展示,目前的话也还是看不到的。 > > > > > > 第二个是我看到metrics里directMemoryUsed总是和所配置的direct内存大小是一样的,不知道具体原因是啥? > > > > > > 要看你所说的“所配置的direct内存大小”是指什么? > > > > > > Thank you~ > > > > Xintong Song > > > > > > [1] > > > > > https://docs.google.com/spreadsheets/d/1mJaMkMPfDJJ-w6nMXALYmTc4XxiV30P5U7DzgwLkSoE/edit#gid=0 > > > > On Tue, Mar 10, 2020 at 12:07 AM pkuvisdudu <[hidden email]> > wrote: > > > > > 多谢解答。 > > > managed memory和network buffers在作业启动后会有调整是在 > > > > > > https://ci.apache.org/projects/flink/flink-docs-release-1.9/ops/mem_setup.html > > > 里看到的,是1.9版本里的。 > > > > > > > > > 还有两个小地方想确认一下,一是您前面说native内存是无法知道使用情况的,那么除了cut-off里的native内存,在Flink 配置项中 > > > task/framework offheap(包括 direct 和 native内存)其中的native内存,以及1.10里managed > > > memory使用的native 内存,是不是也无法在metrics里展示使用情况? > > > 第二个是我看到metrics里directMemoryUsed总是和所配置的direct内存大小是一样的,不知道具体原因是啥? > > > > > > > > > 再次非常感谢~ > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > 在 2020-03-09 18:39:13,"Xintong Song" <[hidden email]> 写道: > > > >> > > > >> 图1中的Direct类型里面所包含的framework offheap、task offheap以及shuffle就是您讲的“不在 > JVM > > > >> 堆上但受到 JVM 管理的内存:Direct”么? > > > > > > > >是的 > > > > > > > > > > > >> 这部分内存是可以知道其使用情况并在metrics里看到的么? > > > > > > > >应该是与metrics中的Direct是对应的(因为绝大多数情况我们没有使用Mapped > Buffer),这里细节我记不太清楚了最好再确认下。 > > > > > > > >另外,flink 1.10里将RocksDBStateBackend改为使用managed memory,不过网页上显示的是managed > > > >> memory统一使用offheap内存,您的解答里说的是native内存,不知道是不是您说的“完全不受 JVM > > 管理的内存:Native”这个? > > > > > > > >是的 > > > > > > > >不是太清楚offheap和direct以及native的关系是怎样的 > > > > > > > >Flink 配置项中的 task/framework offheap,是包括了 direct 和 native > > > >内存算在一起的,也就是说用户不需要关心具体使用的是 direct 还是 native。 > > > > > > > >最后,我在官网上看managed memory和network buffers在作业启动后会有变化 > > > > > > > > > > > > > >能把具体的页面链接发一下吗,可能指的是1.9以前的情况,1.10是不会变化的。1.9以前的话,TM会在进程启动并初始化之后触发一次GC,然后以GC后的空闲内存作为Heap内存重新算一遍managed、network内存应该多大。 > > > > > > > >Thank you~ > > > > > > > >Xintong Song > > > > > > > > > > > > > > > >On Mon, Mar 9, 2020 at 3:23 PM pkuvisdudu <[hidden email]> > > wrote: > > > > > > > >> 非常详细的解答,非常感谢~~ > > > >> > > > >> 还有一些小疑问。图1中的Direct类型里面所包含的framework offheap、task > > > offheap以及shuffle就是您讲的“不在 > > > >> JVM 堆上但受到 JVM 管理的内存:Direct”么?这部分内存是可以知道其使用情况并在metrics里看到的么? > > > >> > > > >> 另外,flink 1.10里将RocksDBStateBackend改为使用managed > memory,不过网页上显示的是managed > > > >> memory统一使用offheap内存,您的解答里说的是native内存,不知道是不是您说的“完全不受 JVM > > > >> 管理的内存:Native”这个?不是太清楚offheap和direct以及native的关系是怎样的 > > > >> > > > >> 最后,我在官网上看managed memory和network > > > >> buffers在作业启动后会有变化,但我一直看不懂是咋变化的,不知道这里能否解答一下 > > > >> > > > >> 再次感谢详细的解答~~ > > > >> > > > >> > > > >> > > > >> > > > >> | | > > > >> 张江 > > > >> | > > > >> | > > > >> 邮箱:[hidden email] > > > >> | > > > >> > > > >> 签名由 网易邮箱大师 定制 > > > >> > > > >> 在2020年03月09日 11:22,Xintong Song 写道: > > > >> Hi, > > > >> > > > >> > > > >> 关于你的几个问题: > > > >> > > > >> > > > >> 1. 关于 JVM 的内存,堆内存(Heap Memory)的定义通常是比较清晰的,但堆外/非堆内存(Off-Heap/Non-Heap > > > >> Memory)的定义却有很多不同的版本,这应该是导致你困惑的主要原因。让我们先抛开这些名词,本质上 Java 应用使用的内存(不包括 > JVM > > > >> 自身的开销)可以分为三类: > > > >> JVM 堆内存:Heap > > > >> 不在 JVM 堆上但受到 JVM 管理的内存:Direct > > > >> 完全不受 JVM 管理的内存:Native > > > >> Direct 内存是直接映射到 JVM 虚拟机外部的内存空间,但是其用量又受到 JVM 的管理和限制,从这个角度来讲,认为它是 JVM > > > 内存或者非 > > > >> JVM 内存都是讲得通的。 > > > >> > > > >> > > > >> 关于 Off-Heap/Non-Heap,广义上讲只要不是 Heap 内存就可以称为 Non-Heap,但是我们经过实验发现 > MXBean > > 的 > > > >> Non-Heap 是不包括 Direct,而是由 Code Cache、Metaspace、Compressed Class Space > > > >> 几个部分组成。FLIP-102 讨论的是 metrics 如何在 WebUI 上展示,Flink metrics 是通过 MXBean > > > >> 获取的,因此图一展示的 Non-Heap 是与 MXBean 的 Non-Heap 定义的。 > > > >> > > > >> > > > >> 2. Heap/Non-Heap 前面已经介绍过,而 Direct/Mapped 则同样是通过 MXBean 统计两个 Buffer > > Pool > > > >> 的情况。这里的 Direct 指的是 Direct Buffer Pool 而不是 Direct Memory,这两个 Buffer > > Pool > > > 都是受 > > > >> -XX:MaxDirectMemorySize 控制的,可以认为都是 Direct Memory 的一部分。 > > > >> > > > >> > > > >> 这几个 metrics 加在一起不是 TM 的总内存,一方面是因为 Native 内存没有被算进去(也就是 Cut-off > > 的主要部分),因为 > > > >> Native 是不受 JVM 管理的,MXBean 完全不知道它的使用情况。另一方面,JVM > > > 自身的开销也并不是都被覆盖到了,比如对于栈空间,JVM > > > >> 只能限制每个线程的栈空间有多大,但是不能限制线程的数量,因此总的栈空间大小也是不受控制的,也没有通过 Metric 来体现。 > > > >> > > > >> > > > >> 总的来说,JVM 的内存机制是非常复杂的,且并不是每一个部分都能够由用户参数控制的。Flink 1.10 > > > >> 简化了内存模型,目的是让用户不需要去关心这其中的细节,只关注 Flink 各功能模块所需的相关内存大小即可。而目前在 1.10 中的 > > > metric > > > >> 是比较缺失的无法完全描述 Flink 的内存使用情况,社区提出 FLIP-102 梳理 metrics 及 UI > > > >> 展示也正是为了解决这个问题。但即便如此,受 JVM 内存机制本身的限制,恐怕也很难做到每个部分都完全匹配到对应的 metrics 上。 > > > >> > > > >> > > > >> 3. 这个应该是存在 state 里的,具体用哪种类型的内存取决于你的 State Backend > > > >> 类型。MemoryStateBackend/FsStateBackend 用的是 Heap 内存,RocksDBStateBackend > > 用的是 > > > >> Native 内存,也就是 1.10 中的 Manage Memory。 > > > >> > > > >> > > > >> > > > >> Thank you~ > > > >> > > > >> Xintong Song > > > >> > > > >> > > > >> > > > >> > > > >> > > > >> On Sun, Mar 8, 2020 at 4:49 PM pkuvisdudu <[hidden email]> > > > wrote: > > > >> > > > >> Hi all, > > > >> > > > >> > > > >> 我是Flink新人,最近在看一些flink资源管理机制的知识,有3个内存类型方面的问题想请教大家: > > > >> > > > >> > > > >> 1. > > > >> > > > > > > Flink的内存类型如下图1所示,其中Heap内存和NonHeap内存由JVM管理,我想问一下Direct内存是否也是由JVM管理?因为我同时也看到过图2所示的内存类型,上面标示的是JVM > > > >> Direct,但在FLIP102里看到的是属于Outside JVM,所以现在有点困惑。另外,我从相关页面上只看到了Network > > > buffers, > > > >> Managed memory, Heap的计算方法,但不知道按照图1所示的内存类型,Direct内存和NonHeap是怎么计算分配的? > > > >> 图1 > > > >> 图2 > > > >> 2. Flink metrics里展示的内存方面的信息以Status.JVM.Memory为前缀,包含Heap, NonHeap, > > > Direct, > > > >> > > > > > > Mapped四种。我测试过,这四种内存Used之和应该并不是TM真正所使用的总内存。那么TM使用的总内存还包括哪些,是在哪里用到的?(不知道是不是cut-off那部分使用的内存?)Flink > > > >> 1.10似乎对内存进行了更细致的划分和分配,但在metrics里展示的内配置和使用信息还是跟1.9一样的么? > > > >> 3. Window相关的算子会将窗口内的数据作为状态保存在内存里,等待窗口触发再进行计算。想问一下这里的状态是存在哪种类型的内存里面? > > > >> > > > >> > > > >> 祝好, > > > >> > > > >> > > > >> > > > >> > > > >> > > > > > > |
|
|
hi, xintong
刚才我在 YARN 上分别测试了四种情况,第一种是默认不修改内存的配置,直接运行作业(Per Job 模式,下面的都是这种模式),作业能够启动起来,能正常运行,内存分配是 Flink 自己分配的; 第二种情况是配置文件指定 taskmanager.memory.managed.size 和 taskmanager.memory.task.heap.size 参数的大小,分别是 1024m 和 256m,作业也能够正常启动运行,截图如下: http://zhisheng-blog.oss-cn-hangzhou.aliyuncs.com/2020-03-10-031628.png 第三种情况是启动的时候通过参数(-ytm 4096m)指定 TM 整个的内存,这种情况我没有修改配置文件的内存分配,也是能够正常运行的,截图如下图所示,这些内存分配应该是根据计算公式算出来的大小 http://zhisheng-blog.oss-cn-hangzhou.aliyuncs.com/2020-03-10-031745.png 第四种情况是启动的时候通过参数(-ytm 4096m)指定 TM 整个的内存,这种情况我自己指定了 taskmanager.memory.managed.size 和 taskmanager.memory.task.heap.size 参数的大小,发现启动作业报异常, Caused by: org.apache.flink.configuration.IllegalConfigurationException: Derived JVM Overhead size (2.236gb (2400539987 bytes)) is not in configured JVM Overhead range [192.000mb (201326592 bytes), 1024.000mb (1073741824 bytes)] http://zhisheng-blog.oss-cn-hangzhou.aliyuncs.com/2020-03-10-032045.png 个人觉得原因可能是因为我指定了taskmanager.memory.managed.size 和 taskmanager.memory.task.heap.size 参数的大小,Flink 就将 4096m 减去指定的大小,然后将剩下来的分配给其他的几种内存,结果超出了 Overhead 的默认最大值,所以检查就返回异常了,不知道是不是这样的原理? 那么就有个问题了,因为在生产环境其实很难知道所有作业的运行状态,所以我们都是这边都是通过 参数(-ytm 4096m)指定 TM 的内存,如果不指定是使用默认的,那么如果和上面情况四一样,既改了配置文件中的配置,又想通过参数(-ytm)去控制整个 TM 的内存,就有冲突了? 对于这种情况,我觉得是不是可以多加个参数控制,这个参数的作用是 heap 内存的 fraction,这样我只需要根据我配置的 fraction 来分配总的内存值,因为我看 managed 和 network、overhead 这些都是有这个参数的 eg: taskmanager.memory.task.heap.fraction 不清楚这个建议是否得当,感谢! Xintong Song <[hidden email]> 于2020年3月10日周二 上午10:39写道: > > > > 这里的“所配置的direct内存”,是指按照task.manager.network.memory.fraction计算得到的network > > memory大小。我想是不是这部分内存按照memory segment全部预分配了,所有metrics里显示的是全部是被Used了? > > > 是的,Network Buffer Pool 是在 TM 初始化时预申请好的。在所有内存类型中,只有 Network Memory > 是预申请的。Managed Memory 1.9 以前是有一个配置可以预申请(默认不开),1.10 起不再支持预申请。 > > > Thank you~ > > Xintong Song > > > > On Tue, Mar 10, 2020 at 10:30 AM pkuvisdudu <[hidden email]> wrote: > > > 多谢解答。 > > 关于“第二个是我看到metrics里directMemoryUsed总是和所配置的direct内存大小是一样的,不知道具体原因是啥?” > > 这里的“所配置的direct内存”,是指按照task.manager.network.memory.fraction计算得到的network > > memory大小。我想是不是这部分内存按照memory segment全部预分配了,所有metrics里显示的是全部是被Used了? > > > > > > > > > > | | > > 张江 > > | > > | > > 邮箱:[hidden email] > > | > > > > 签名由 网易邮箱大师 定制 > > > > 在2020年03月10日 10:16,zhisheng 写道: > > hi,xintong,感谢耐心且专业的回答👍 > > > > Xintong Song <[hidden email]> 于2020年3月10日周二 上午10:04写道: > > > > > Hi Zhisheng, > > > > > > 1、Non-Heap 那个 UI 上展示的是否是 MetaSpace 和 Overhead 加起来的值? > > > > > > > > > 从物理含义上来说,Non-Heap 描述的内存开销是包含在 Metaspace + Overhead 里的。 > > > > > > > > > > 2、为什么本地起的 Standalone Flink,为啥 UI 上展示的 Heap 会超过设置的 > > > > taskmanager.memory.process.size 的值? > > > > > > > > > 这主要是因为,我们只针对 Metaspace 设置了 JVM 的参数,对于其他 Overhead 并没有设置 JVM 的参数,也并不是所有的 > > > Overhead 都有参数可以控制(比如栈空间)。 > > > > > > Non-Heap Max 是 JVM 自己决定的,所以通常会比 Flink 配置的 Metaspace + Overhead > > > 要大。可以这样理解,Flink 将整个 TM 的内存预算划分给了不同的用途,但是并不能严格保证各部分的内存都不超用,只能是 Best > > > Effort。其中,Managed、Network、Metaspace 是严格限制的,Off-Heap、Overhead > > > 是不能完全严格限制的,Heap 整体是严格限制的但是 Task/Framework 之间是非严格的。 > > > > > > Non-Heap 这个 metric 对用户的意义不大,且容易造成用户误解。FLIP-102 目前还在讨论中,我们也在给 Yadong > > > 提建议是否就不展示 Non-Heap了。 > > > > > > 3、默认 Flink 自身的配置下,启动 Flink 1.9 和 > > > > > > 1.10,运行相同的作业他们性能之间的差距大概是什么样的?如果上生产是否可以使用默认的内存配置?会不会堆内存有点小了?这个我说下我自己简单测试了下 > > > > Flink 1.9 和 1.10 下运行同一个有状态的作业,他们的 GC 情况差别还挺大的。1.10 Young GC 次数差不多是 > 1.9 > > > 的两倍。 > > > > > > > > > 1.10 默认配置比起 1.9,减小了 Heap 增大了 Managed,可以参考 Memory Calculation Sheet [1] > 中的 > > > 1.9/1.10 > > > > > > > > > 默认配置各部分内存大小对比(可以把这个表复制到自己的空间取得写权限,对各配置项的值进行修改可以直接看到各部分内存大小的变化)。至于对作业性能的影响,主要取决于作业类型(流还是批、statebackend类型等),没法一概而论。默认配置主要考虑的是用户初始尝试 > > > Flink 的需求,如果上生产的话,通常是需要改配置的。 > > > > > > > > > Hi 张江, > > > > > > > > > 一是您前面说native内存是无法知道使用情况的,那么除了cut-off里的native内存,在Flink 配置项中 > task/framework > > > > offheap(包括 direct 和 native内存)其中的native内存,以及1.10里managed > memory使用的native > > > > 内存,是不是也无法在metrics里展示使用情况? > > > > > > > > > Task/Framework OffHeap 也无法在 metrics 里展示。Managed Memory 理论上 Flink > > > 自己有统计,我们也在考虑增加相应的 metrics 展示,目前的话也还是看不到的。 > > > > > > > > > 第二个是我看到metrics里directMemoryUsed总是和所配置的direct内存大小是一样的,不知道具体原因是啥? > > > > > > > > > 要看你所说的“所配置的direct内存大小”是指什么? > > > > > > > > > Thank you~ > > > > > > Xintong Song > > > > > > > > > [1] > > > > > > > > > https://docs.google.com/spreadsheets/d/1mJaMkMPfDJJ-w6nMXALYmTc4XxiV30P5U7DzgwLkSoE/edit#gid=0 > > > > > > On Tue, Mar 10, 2020 at 12:07 AM pkuvisdudu <[hidden email]> > > wrote: > > > > > > > 多谢解答。 > > > > managed memory和network buffers在作业启动后会有调整是在 > > > > > > > > > > https://ci.apache.org/projects/flink/flink-docs-release-1.9/ops/mem_setup.html > > > > 里看到的,是1.9版本里的。 > > > > > > > > > > > > 还有两个小地方想确认一下,一是您前面说native内存是无法知道使用情况的,那么除了cut-off里的native内存,在Flink > 配置项中 > > > > task/framework offheap(包括 direct 和 > native内存)其中的native内存,以及1.10里managed > > > > memory使用的native 内存,是不是也无法在metrics里展示使用情况? > > > > 第二个是我看到metrics里directMemoryUsed总是和所配置的direct内存大小是一样的,不知道具体原因是啥? > > > > > > > > > > > > 再次非常感谢~ > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > 在 2020-03-09 18:39:13,"Xintong Song" <[hidden email]> 写道: > > > > >> > > > > >> 图1中的Direct类型里面所包含的framework offheap、task offheap以及shuffle就是您讲的“不在 > > JVM > > > > >> 堆上但受到 JVM 管理的内存:Direct”么? > > > > > > > > > >是的 > > > > > > > > > > > > > > >> 这部分内存是可以知道其使用情况并在metrics里看到的么? > > > > > > > > > >应该是与metrics中的Direct是对应的(因为绝大多数情况我们没有使用Mapped > > Buffer),这里细节我记不太清楚了最好再确认下。 > > > > > > > > > >另外,flink 1.10里将RocksDBStateBackend改为使用managed > memory,不过网页上显示的是managed > > > > >> memory统一使用offheap内存,您的解答里说的是native内存,不知道是不是您说的“完全不受 JVM > > > 管理的内存:Native”这个? > > > > > > > > > >是的 > > > > > > > > > >不是太清楚offheap和direct以及native的关系是怎样的 > > > > > > > > > >Flink 配置项中的 task/framework offheap,是包括了 direct 和 native > > > > >内存算在一起的,也就是说用户不需要关心具体使用的是 direct 还是 native。 > > > > > > > > > >最后,我在官网上看managed memory和network buffers在作业启动后会有变化 > > > > > > > > > > > > > > > > > > > >能把具体的页面链接发一下吗,可能指的是1.9以前的情况,1.10是不会变化的。1.9以前的话,TM会在进程启动并初始化之后触发一次GC,然后以GC后的空闲内存作为Heap内存重新算一遍managed、network内存应该多大。 > > > > > > > > > >Thank you~ > > > > > > > > > >Xintong Song > > > > > > > > > > > > > > > > > > > >On Mon, Mar 9, 2020 at 3:23 PM pkuvisdudu <[hidden email]> > > > wrote: > > > > > > > > > >> 非常详细的解答,非常感谢~~ > > > > >> > > > > >> 还有一些小疑问。图1中的Direct类型里面所包含的framework offheap、task > > > > offheap以及shuffle就是您讲的“不在 > > > > >> JVM 堆上但受到 JVM 管理的内存:Direct”么?这部分内存是可以知道其使用情况并在metrics里看到的么? > > > > >> > > > > >> 另外,flink 1.10里将RocksDBStateBackend改为使用managed > > memory,不过网页上显示的是managed > > > > >> memory统一使用offheap内存,您的解答里说的是native内存,不知道是不是您说的“完全不受 JVM > > > > >> 管理的内存:Native”这个?不是太清楚offheap和direct以及native的关系是怎样的 > > > > >> > > > > >> 最后,我在官网上看managed memory和network > > > > >> buffers在作业启动后会有变化,但我一直看不懂是咋变化的,不知道这里能否解答一下 > > > > >> > > > > >> 再次感谢详细的解答~~ > > > > >> > > > > >> > > > > >> > > > > >> > > > > >> | | > > > > >> 张江 > > > > >> | > > > > >> | > > > > >> 邮箱:[hidden email] > > > > >> | > > > > >> > > > > >> 签名由 网易邮箱大师 定制 > > > > >> > > > > >> 在2020年03月09日 11:22,Xintong Song 写道: > > > > >> Hi, > > > > >> > > > > >> > > > > >> 关于你的几个问题: > > > > >> > > > > >> > > > > >> 1. 关于 JVM 的内存,堆内存(Heap > Memory)的定义通常是比较清晰的,但堆外/非堆内存(Off-Heap/Non-Heap > > > > >> Memory)的定义却有很多不同的版本,这应该是导致你困惑的主要原因。让我们先抛开这些名词,本质上 Java 应用使用的内存(不包括 > > JVM > > > > >> 自身的开销)可以分为三类: > > > > >> JVM 堆内存:Heap > > > > >> 不在 JVM 堆上但受到 JVM 管理的内存:Direct > > > > >> 完全不受 JVM 管理的内存:Native > > > > >> Direct 内存是直接映射到 JVM 虚拟机外部的内存空间,但是其用量又受到 JVM 的管理和限制,从这个角度来讲,认为它是 > JVM > > > > 内存或者非 > > > > >> JVM 内存都是讲得通的。 > > > > >> > > > > >> > > > > >> 关于 Off-Heap/Non-Heap,广义上讲只要不是 Heap 内存就可以称为 Non-Heap,但是我们经过实验发现 > > MXBean > > > 的 > > > > >> Non-Heap 是不包括 Direct,而是由 Code Cache、Metaspace、Compressed Class > Space > > > > >> 几个部分组成。FLIP-102 讨论的是 metrics 如何在 WebUI 上展示,Flink metrics 是通过 > MXBean > > > > >> 获取的,因此图一展示的 Non-Heap 是与 MXBean 的 Non-Heap 定义的。 > > > > >> > > > > >> > > > > >> 2. Heap/Non-Heap 前面已经介绍过,而 Direct/Mapped 则同样是通过 MXBean 统计两个 Buffer > > > Pool > > > > >> 的情况。这里的 Direct 指的是 Direct Buffer Pool 而不是 Direct Memory,这两个 Buffer > > > Pool > > > > 都是受 > > > > >> -XX:MaxDirectMemorySize 控制的,可以认为都是 Direct Memory 的一部分。 > > > > >> > > > > >> > > > > >> 这几个 metrics 加在一起不是 TM 的总内存,一方面是因为 Native 内存没有被算进去(也就是 Cut-off > > > 的主要部分),因为 > > > > >> Native 是不受 JVM 管理的,MXBean 完全不知道它的使用情况。另一方面,JVM > > > > 自身的开销也并不是都被覆盖到了,比如对于栈空间,JVM > > > > >> 只能限制每个线程的栈空间有多大,但是不能限制线程的数量,因此总的栈空间大小也是不受控制的,也没有通过 Metric 来体现。 > > > > >> > > > > >> > > > > >> 总的来说,JVM 的内存机制是非常复杂的,且并不是每一个部分都能够由用户参数控制的。Flink 1.10 > > > > >> 简化了内存模型,目的是让用户不需要去关心这其中的细节,只关注 Flink 各功能模块所需的相关内存大小即可。而目前在 1.10 中的 > > > > metric > > > > >> 是比较缺失的无法完全描述 Flink 的内存使用情况,社区提出 FLIP-102 梳理 metrics 及 UI > > > > >> 展示也正是为了解决这个问题。但即便如此,受 JVM 内存机制本身的限制,恐怕也很难做到每个部分都完全匹配到对应的 metrics > 上。 > > > > >> > > > > >> > > > > >> 3. 这个应该是存在 state 里的,具体用哪种类型的内存取决于你的 State Backend > > > > >> 类型。MemoryStateBackend/FsStateBackend 用的是 Heap > 内存,RocksDBStateBackend > > > 用的是 > > > > >> Native 内存,也就是 1.10 中的 Manage Memory。 > > > > >> > > > > >> > > > > >> > > > > >> Thank you~ > > > > >> > > > > >> Xintong Song > > > > >> > > > > >> > > > > >> > > > > >> > > > > >> > > > > >> On Sun, Mar 8, 2020 at 4:49 PM pkuvisdudu <[hidden email]> > > > > wrote: > > > > >> > > > > >> Hi all, > > > > >> > > > > >> > > > > >> 我是Flink新人,最近在看一些flink资源管理机制的知识,有3个内存类型方面的问题想请教大家: > > > > >> > > > > >> > > > > >> 1. > > > > >> > > > > > > > > > > Flink的内存类型如下图1所示,其中Heap内存和NonHeap内存由JVM管理,我想问一下Direct内存是否也是由JVM管理?因为我同时也看到过图2所示的内存类型,上面标示的是JVM > > > > >> Direct,但在FLIP102里看到的是属于Outside JVM,所以现在有点困惑。另外,我从相关页面上只看到了Network > > > > buffers, > > > > >> Managed memory, > Heap的计算方法,但不知道按照图1所示的内存类型,Direct内存和NonHeap是怎么计算分配的? > > > > >> 图1 > > > > >> 图2 > > > > >> 2. Flink metrics里展示的内存方面的信息以Status.JVM.Memory为前缀,包含Heap, NonHeap, > > > > Direct, > > > > >> > > > > > > > > > > Mapped四种。我测试过,这四种内存Used之和应该并不是TM真正所使用的总内存。那么TM使用的总内存还包括哪些,是在哪里用到的?(不知道是不是cut-off那部分使用的内存?)Flink > > > > >> 1.10似乎对内存进行了更细致的划分和分配,但在metrics里展示的内配置和使用信息还是跟1.9一样的么? > > > > >> 3. > Window相关的算子会将窗口内的数据作为状态保存在内存里,等待窗口触发再进行计算。想问一下这里的状态是存在哪种类型的内存里面? > > > > >> > > > > >> > > > > >> 祝好, > > > > >> > > > > >> > > > > >> > > > > >> > > > > >> > > > > > > > > > > |
|
|
Hi Zhisheng,
首先,Flink 官方的内存配置文档 [1] 中明确表示了,不推荐同时配置 process.size、flink.size、task.heap.size + managed.size 三者中的任意两种或以上。 > Explicitly configuring both *total process memory* and *total Flink > memory* is not recommended. It may lead to deployment failures due to > potential memory configuration conflicts. Additional configuration of other > memory components also requires caution as it can produce further > configuration conflicts. 要理解为什么会有这样的建议,首先需要理解 Flink 的内存配置中有严格和非严格的差别。 - 所有的 size/min/max 都是严格保证的,不管是用户显式配置还是用户没配但是有默认值,都会保证生效,或者因冲突而报错。 - 所有的 fraction 都是非严格的,不保证最后算出的内存大小一定满足配置的 fraction。例如,如果根据 fraction 算出的 network memory 超过了 max,那么会使用 max 值且不会报错。 目前所有内存类型中,大部分都是有严格的默认大小(size)或者默认范围(min/max)的,没有严格默认值的只有: - 总内存:process.size/flink.size 均没有默认值 - Task Heap:task.heap.size 没有默认值 - Managed:managed.size 没有默认值,managed.fraction 是非严格的 如果所有的内存部分都有配置指定了严格的内存大小或范围,那么总内存的大小或范围也就确定了,这时候如果再另外指定总内存的大小,就有可能产生冲突。这也就是为什么不建议用户同时配置以上几项的原因。 至于你提到的 task.heap.fraction,实际上在指定了总的 flink.size 和 Managed、Network 部分的 fraction 之后,Heap 的大小就是确定的了(因为其他部分都是严格确定的大小),这个时候再指定 Heap 的 fraction 意义不大。同理,指定 process.size 的情况只是多考虑了 JVM-Overhead 的 fraction。其实 task.heap.fraction 这个需求完全可以通过修改 network.fraction 和 managed.fraction 来实现,设置 Network 和 Managed 用的内存少了,那么总内存中多出来的部分自然就留给 Heap 了。 Thank you~ Xintong Song [1] https://ci.apache.org/projects/flink/flink-docs-release-1.10/ops/memory/mem_setup.html On Tue, Mar 10, 2020 at 11:40 AM zhisheng <[hidden email]> wrote: > hi, xintong > > 刚才我在 YARN 上分别测试了四种情况,第一种是默认不修改内存的配置,直接运行作业(Per Job > 模式,下面的都是这种模式),作业能够启动起来,能正常运行,内存分配是 Flink 自己分配的; > > 第二种情况是配置文件指定 taskmanager.memory.managed.size > 和 taskmanager.memory.task.heap.size 参数的大小,分别是 1024m 和 > 256m,作业也能够正常启动运行,截图如下: > > http://zhisheng-blog.oss-cn-hangzhou.aliyuncs.com/2020-03-10-031628.png > > 第三种情况是启动的时候通过参数(-ytm 4096m)指定 TM > 整个的内存,这种情况我没有修改配置文件的内存分配,也是能够正常运行的,截图如下图所示,这些内存分配应该是根据计算公式算出来的大小 > > http://zhisheng-blog.oss-cn-hangzhou.aliyuncs.com/2020-03-10-031745.png > > 第四种情况是启动的时候通过参数(-ytm 4096m)指定 TM 整个的内存,这种情况我自己指定了 > taskmanager.memory.managed.size 和 taskmanager.memory.task.heap.size > 参数的大小,发现启动作业报异常, > > Caused by: org.apache.flink.configuration.IllegalConfigurationException: > Derived JVM Overhead size (2.236gb (2400539987 bytes)) is not in configured > JVM Overhead range [192.000mb (201326592 bytes), 1024.000mb (1073741824 > bytes)] > > http://zhisheng-blog.oss-cn-hangzhou.aliyuncs.com/2020-03-10-032045.png > > 个人觉得原因可能是因为我指定了taskmanager.memory.managed.size > 和 taskmanager.memory.task.heap.size 参数的大小,Flink 就将 4096m > 减去指定的大小,然后将剩下来的分配给其他的几种内存,结果超出了 Overhead 的默认最大值,所以检查就返回异常了,不知道是不是这样的原理? > > 那么就有个问题了,因为在生产环境其实很难知道所有作业的运行状态,所以我们都是这边都是通过 参数(-ytm 4096m)指定 TM > 的内存,如果不指定是使用默认的,那么如果和上面情况四一样,既改了配置文件中的配置,又想通过参数(-ytm)去控制整个 TM 的内存,就有冲突了? > > 对于这种情况,我觉得是不是可以多加个参数控制,这个参数的作用是 heap 内存的 fraction,这样我只需要根据我配置的 fraction > 来分配总的内存值,因为我看 managed 和 network、overhead 这些都是有这个参数的 > > eg: > taskmanager.memory.task.heap.fraction > > 不清楚这个建议是否得当,感谢! > > Xintong Song <[hidden email]> 于2020年3月10日周二 上午10:39写道: > > > > > > > 这里的“所配置的direct内存”,是指按照task.manager.network.memory.fraction计算得到的network > > > memory大小。我想是不是这部分内存按照memory segment全部预分配了,所有metrics里显示的是全部是被Used了? > > > > > > 是的,Network Buffer Pool 是在 TM 初始化时预申请好的。在所有内存类型中,只有 Network Memory > > 是预申请的。Managed Memory 1.9 以前是有一个配置可以预申请(默认不开),1.10 起不再支持预申请。 > > > > > > Thank you~ > > > > Xintong Song > > > > > > > > On Tue, Mar 10, 2020 at 10:30 AM pkuvisdudu <[hidden email]> > wrote: > > > > > 多谢解答。 > > > 关于“第二个是我看到metrics里directMemoryUsed总是和所配置的direct内存大小是一样的,不知道具体原因是啥?” > > > 这里的“所配置的direct内存”,是指按照task.manager.network.memory.fraction计算得到的network > > > memory大小。我想是不是这部分内存按照memory segment全部预分配了,所有metrics里显示的是全部是被Used了? > > > > > > > > > > > > > > > | | > > > 张江 > > > | > > > | > > > 邮箱:[hidden email] > > > | > > > > > > 签名由 网易邮箱大师 定制 > > > > > > 在2020年03月10日 10:16,zhisheng 写道: > > > hi,xintong,感谢耐心且专业的回答👍 > > > > > > Xintong Song <[hidden email]> 于2020年3月10日周二 上午10:04写道: > > > > > > > Hi Zhisheng, > > > > > > > > 1、Non-Heap 那个 UI 上展示的是否是 MetaSpace 和 Overhead 加起来的值? > > > > > > > > > > > > 从物理含义上来说,Non-Heap 描述的内存开销是包含在 Metaspace + Overhead 里的。 > > > > > > > > > > > > > 2、为什么本地起的 Standalone Flink,为啥 UI 上展示的 Heap 会超过设置的 > > > > > taskmanager.memory.process.size 的值? > > > > > > > > > > > > 这主要是因为,我们只针对 Metaspace 设置了 JVM 的参数,对于其他 Overhead 并没有设置 JVM > 的参数,也并不是所有的 > > > > Overhead 都有参数可以控制(比如栈空间)。 > > > > > > > > Non-Heap Max 是 JVM 自己决定的,所以通常会比 Flink 配置的 Metaspace + Overhead > > > > 要大。可以这样理解,Flink 将整个 TM 的内存预算划分给了不同的用途,但是并不能严格保证各部分的内存都不超用,只能是 Best > > > > Effort。其中,Managed、Network、Metaspace 是严格限制的,Off-Heap、Overhead > > > > 是不能完全严格限制的,Heap 整体是严格限制的但是 Task/Framework 之间是非严格的。 > > > > > > > > Non-Heap 这个 metric 对用户的意义不大,且容易造成用户误解。FLIP-102 目前还在讨论中,我们也在给 Yadong > > > > 提建议是否就不展示 Non-Heap了。 > > > > > > > > 3、默认 Flink 自身的配置下,启动 Flink 1.9 和 > > > > > > > > > 1.10,运行相同的作业他们性能之间的差距大概是什么样的?如果上生产是否可以使用默认的内存配置?会不会堆内存有点小了?这个我说下我自己简单测试了下 > > > > > Flink 1.9 和 1.10 下运行同一个有状态的作业,他们的 GC 情况差别还挺大的。1.10 Young GC 次数差不多是 > > 1.9 > > > > 的两倍。 > > > > > > > > > > > > 1.10 默认配置比起 1.9,减小了 Heap 增大了 Managed,可以参考 Memory Calculation Sheet > [1] > > 中的 > > > > 1.9/1.10 > > > > > > > > > > > > > > 默认配置各部分内存大小对比(可以把这个表复制到自己的空间取得写权限,对各配置项的值进行修改可以直接看到各部分内存大小的变化)。至于对作业性能的影响,主要取决于作业类型(流还是批、statebackend类型等),没法一概而论。默认配置主要考虑的是用户初始尝试 > > > > Flink 的需求,如果上生产的话,通常是需要改配置的。 > > > > > > > > > > > > Hi 张江, > > > > > > > > > > > > 一是您前面说native内存是无法知道使用情况的,那么除了cut-off里的native内存,在Flink 配置项中 > > task/framework > > > > > offheap(包括 direct 和 native内存)其中的native内存,以及1.10里managed > > memory使用的native > > > > > 内存,是不是也无法在metrics里展示使用情况? > > > > > > > > > > > > Task/Framework OffHeap 也无法在 metrics 里展示。Managed Memory 理论上 Flink > > > > 自己有统计,我们也在考虑增加相应的 metrics 展示,目前的话也还是看不到的。 > > > > > > > > > > > > 第二个是我看到metrics里directMemoryUsed总是和所配置的direct内存大小是一样的,不知道具体原因是啥? > > > > > > > > > > > > 要看你所说的“所配置的direct内存大小”是指什么? > > > > > > > > > > > > Thank you~ > > > > > > > > Xintong Song > > > > > > > > > > > > [1] > > > > > > > > > > > > > > https://docs.google.com/spreadsheets/d/1mJaMkMPfDJJ-w6nMXALYmTc4XxiV30P5U7DzgwLkSoE/edit#gid=0 > > > > > > > > On Tue, Mar 10, 2020 at 12:07 AM pkuvisdudu <[hidden email]> > > > wrote: > > > > > > > > > 多谢解答。 > > > > > managed memory和network buffers在作业启动后会有调整是在 > > > > > > > > > > > > > > > https://ci.apache.org/projects/flink/flink-docs-release-1.9/ops/mem_setup.html > > > > > 里看到的,是1.9版本里的。 > > > > > > > > > > > > > > > 还有两个小地方想确认一下,一是您前面说native内存是无法知道使用情况的,那么除了cut-off里的native内存,在Flink > > 配置项中 > > > > > task/framework offheap(包括 direct 和 > > native内存)其中的native内存,以及1.10里managed > > > > > memory使用的native 内存,是不是也无法在metrics里展示使用情况? > > > > > 第二个是我看到metrics里directMemoryUsed总是和所配置的direct内存大小是一样的,不知道具体原因是啥? > > > > > > > > > > > > > > > 再次非常感谢~ > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > 在 2020-03-09 18:39:13,"Xintong Song" <[hidden email]> 写道: > > > > > >> > > > > > >> 图1中的Direct类型里面所包含的framework offheap、task > offheap以及shuffle就是您讲的“不在 > > > JVM > > > > > >> 堆上但受到 JVM 管理的内存:Direct”么? > > > > > > > > > > > >是的 > > > > > > > > > > > > > > > > > >> 这部分内存是可以知道其使用情况并在metrics里看到的么? > > > > > > > > > > > >应该是与metrics中的Direct是对应的(因为绝大多数情况我们没有使用Mapped > > > Buffer),这里细节我记不太清楚了最好再确认下。 > > > > > > > > > > > >另外,flink 1.10里将RocksDBStateBackend改为使用managed > > memory,不过网页上显示的是managed > > > > > >> memory统一使用offheap内存,您的解答里说的是native内存,不知道是不是您说的“完全不受 JVM > > > > 管理的内存:Native”这个? > > > > > > > > > > > >是的 > > > > > > > > > > > >不是太清楚offheap和direct以及native的关系是怎样的 > > > > > > > > > > > >Flink 配置项中的 task/framework offheap,是包括了 direct 和 native > > > > > >内存算在一起的,也就是说用户不需要关心具体使用的是 direct 还是 native。 > > > > > > > > > > > >最后,我在官网上看managed memory和network buffers在作业启动后会有变化 > > > > > > > > > > > > > > > > > > > > > > > > > > >能把具体的页面链接发一下吗,可能指的是1.9以前的情况,1.10是不会变化的。1.9以前的话,TM会在进程启动并初始化之后触发一次GC,然后以GC后的空闲内存作为Heap内存重新算一遍managed、network内存应该多大。 > > > > > > > > > > > >Thank you~ > > > > > > > > > > > >Xintong Song > > > > > > > > > > > > > > > > > > > > > > > >On Mon, Mar 9, 2020 at 3:23 PM pkuvisdudu <[hidden email]> > > > > wrote: > > > > > > > > > > > >> 非常详细的解答,非常感谢~~ > > > > > >> > > > > > >> 还有一些小疑问。图1中的Direct类型里面所包含的framework offheap、task > > > > > offheap以及shuffle就是您讲的“不在 > > > > > >> JVM 堆上但受到 JVM 管理的内存:Direct”么?这部分内存是可以知道其使用情况并在metrics里看到的么? > > > > > >> > > > > > >> 另外,flink 1.10里将RocksDBStateBackend改为使用managed > > > memory,不过网页上显示的是managed > > > > > >> memory统一使用offheap内存,您的解答里说的是native内存,不知道是不是您说的“完全不受 JVM > > > > > >> 管理的内存:Native”这个?不是太清楚offheap和direct以及native的关系是怎样的 > > > > > >> > > > > > >> 最后,我在官网上看managed memory和network > > > > > >> buffers在作业启动后会有变化,但我一直看不懂是咋变化的,不知道这里能否解答一下 > > > > > >> > > > > > >> 再次感谢详细的解答~~ > > > > > >> > > > > > >> > > > > > >> > > > > > >> > > > > > >> | | > > > > > >> 张江 > > > > > >> | > > > > > >> | > > > > > >> 邮箱:[hidden email] > > > > > >> | > > > > > >> > > > > > >> 签名由 网易邮箱大师 定制 > > > > > >> > > > > > >> 在2020年03月09日 11:22,Xintong Song 写道: > > > > > >> Hi, > > > > > >> > > > > > >> > > > > > >> 关于你的几个问题: > > > > > >> > > > > > >> > > > > > >> 1. 关于 JVM 的内存,堆内存(Heap > > Memory)的定义通常是比较清晰的,但堆外/非堆内存(Off-Heap/Non-Heap > > > > > >> Memory)的定义却有很多不同的版本,这应该是导致你困惑的主要原因。让我们先抛开这些名词,本质上 Java > 应用使用的内存(不包括 > > > JVM > > > > > >> 自身的开销)可以分为三类: > > > > > >> JVM 堆内存:Heap > > > > > >> 不在 JVM 堆上但受到 JVM 管理的内存:Direct > > > > > >> 完全不受 JVM 管理的内存:Native > > > > > >> Direct 内存是直接映射到 JVM 虚拟机外部的内存空间,但是其用量又受到 JVM 的管理和限制,从这个角度来讲,认为它是 > > JVM > > > > > 内存或者非 > > > > > >> JVM 内存都是讲得通的。 > > > > > >> > > > > > >> > > > > > >> 关于 Off-Heap/Non-Heap,广义上讲只要不是 Heap 内存就可以称为 Non-Heap,但是我们经过实验发现 > > > MXBean > > > > 的 > > > > > >> Non-Heap 是不包括 Direct,而是由 Code Cache、Metaspace、Compressed Class > > Space > > > > > >> 几个部分组成。FLIP-102 讨论的是 metrics 如何在 WebUI 上展示,Flink metrics 是通过 > > MXBean > > > > > >> 获取的,因此图一展示的 Non-Heap 是与 MXBean 的 Non-Heap 定义的。 > > > > > >> > > > > > >> > > > > > >> 2. Heap/Non-Heap 前面已经介绍过,而 Direct/Mapped 则同样是通过 MXBean 统计两个 > Buffer > > > > Pool > > > > > >> 的情况。这里的 Direct 指的是 Direct Buffer Pool 而不是 Direct Memory,这两个 > Buffer > > > > Pool > > > > > 都是受 > > > > > >> -XX:MaxDirectMemorySize 控制的,可以认为都是 Direct Memory 的一部分。 > > > > > >> > > > > > >> > > > > > >> 这几个 metrics 加在一起不是 TM 的总内存,一方面是因为 Native 内存没有被算进去(也就是 Cut-off > > > > 的主要部分),因为 > > > > > >> Native 是不受 JVM 管理的,MXBean 完全不知道它的使用情况。另一方面,JVM > > > > > 自身的开销也并不是都被覆盖到了,比如对于栈空间,JVM > > > > > >> 只能限制每个线程的栈空间有多大,但是不能限制线程的数量,因此总的栈空间大小也是不受控制的,也没有通过 Metric 来体现。 > > > > > >> > > > > > >> > > > > > >> 总的来说,JVM 的内存机制是非常复杂的,且并不是每一个部分都能够由用户参数控制的。Flink 1.10 > > > > > >> 简化了内存模型,目的是让用户不需要去关心这其中的细节,只关注 Flink 各功能模块所需的相关内存大小即可。而目前在 1.10 > 中的 > > > > > metric > > > > > >> 是比较缺失的无法完全描述 Flink 的内存使用情况,社区提出 FLIP-102 梳理 metrics 及 UI > > > > > >> 展示也正是为了解决这个问题。但即便如此,受 JVM 内存机制本身的限制,恐怕也很难做到每个部分都完全匹配到对应的 metrics > > 上。 > > > > > >> > > > > > >> > > > > > >> 3. 这个应该是存在 state 里的,具体用哪种类型的内存取决于你的 State Backend > > > > > >> 类型。MemoryStateBackend/FsStateBackend 用的是 Heap > > 内存,RocksDBStateBackend > > > > 用的是 > > > > > >> Native 内存,也就是 1.10 中的 Manage Memory。 > > > > > >> > > > > > >> > > > > > >> > > > > > >> Thank you~ > > > > > >> > > > > > >> Xintong Song > > > > > >> > > > > > >> > > > > > >> > > > > > >> > > > > > >> > > > > > >> On Sun, Mar 8, 2020 at 4:49 PM pkuvisdudu < > [hidden email]> > > > > > wrote: > > > > > >> > > > > > >> Hi all, > > > > > >> > > > > > >> > > > > > >> 我是Flink新人,最近在看一些flink资源管理机制的知识,有3个内存类型方面的问题想请教大家: > > > > > >> > > > > > >> > > > > > >> 1. > > > > > >> > > > > > > > > > > > > > > > Flink的内存类型如下图1所示,其中Heap内存和NonHeap内存由JVM管理,我想问一下Direct内存是否也是由JVM管理?因为我同时也看到过图2所示的内存类型,上面标示的是JVM > > > > > >> Direct,但在FLIP102里看到的是属于Outside > JVM,所以现在有点困惑。另外,我从相关页面上只看到了Network > > > > > buffers, > > > > > >> Managed memory, > > Heap的计算方法,但不知道按照图1所示的内存类型,Direct内存和NonHeap是怎么计算分配的? > > > > > >> 图1 > > > > > >> 图2 > > > > > >> 2. Flink metrics里展示的内存方面的信息以Status.JVM.Memory为前缀,包含Heap, > NonHeap, > > > > > Direct, > > > > > >> > > > > > > > > > > > > > > > Mapped四种。我测试过,这四种内存Used之和应该并不是TM真正所使用的总内存。那么TM使用的总内存还包括哪些,是在哪里用到的?(不知道是不是cut-off那部分使用的内存?)Flink > > > > > >> 1.10似乎对内存进行了更细致的划分和分配,但在metrics里展示的内配置和使用信息还是跟1.9一样的么? > > > > > >> 3. > > Window相关的算子会将窗口内的数据作为状态保存在内存里,等待窗口触发再进行计算。想问一下这里的状态是存在哪种类型的内存里面? > > > > > >> > > > > > >> > > > > > >> 祝好, > > > > > >> > > > > > >> > > > > > >> > > > > > >> > > > > > >> > > > > > > > > > > > > > > > |
|
|
好的,清楚了,感谢
Xintong Song <[hidden email]> 于2020年3月10日周二 下午12:43写道: > Hi Zhisheng, > > 首先,Flink 官方的内存配置文档 [1] 中明确表示了,不推荐同时配置 > process.size、flink.size、task.heap.size + managed.size 三者中的任意两种或以上。 > > > Explicitly configuring both *total process memory* and *total Flink > > memory* is not recommended. It may lead to deployment failures due to > > potential memory configuration conflicts. Additional configuration of > other > > memory components also requires caution as it can produce further > > configuration conflicts. > > > 要理解为什么会有这样的建议,首先需要理解 Flink 的内存配置中有严格和非严格的差别。 > > - 所有的 size/min/max 都是严格保证的,不管是用户显式配置还是用户没配但是有默认值,都会保证生效,或者因冲突而报错。 > - 所有的 fraction 都是非严格的,不保证最后算出的内存大小一定满足配置的 fraction。例如,如果根据 fraction 算出的 > network memory 超过了 max,那么会使用 max 值且不会报错。 > > 目前所有内存类型中,大部分都是有严格的默认大小(size)或者默认范围(min/max)的,没有严格默认值的只有: > > - 总内存:process.size/flink.size 均没有默认值 > - Task Heap:task.heap.size 没有默认值 > - Managed:managed.size 没有默认值,managed.fraction 是非严格的 > > > 如果所有的内存部分都有配置指定了严格的内存大小或范围,那么总内存的大小或范围也就确定了,这时候如果再另外指定总内存的大小,就有可能产生冲突。这也就是为什么不建议用户同时配置以上几项的原因。 > > 至于你提到的 task.heap.fraction,实际上在指定了总的 flink.size 和 Managed、Network 部分的 > fraction 之后,Heap 的大小就是确定的了(因为其他部分都是严格确定的大小),这个时候再指定 Heap 的 fraction > 意义不大。同理,指定 process.size 的情况只是多考虑了 JVM-Overhead 的 fraction。其实 > task.heap.fraction 这个需求完全可以通过修改 network.fraction 和 managed.fraction 来实现,设置 > Network 和 Managed 用的内存少了,那么总内存中多出来的部分自然就留给 Heap 了。 > > Thank you~ > > Xintong Song > > > [1] > > https://ci.apache.org/projects/flink/flink-docs-release-1.10/ops/memory/mem_setup.html > > On Tue, Mar 10, 2020 at 11:40 AM zhisheng <[hidden email]> wrote: > > > hi, xintong > > > > 刚才我在 YARN 上分别测试了四种情况,第一种是默认不修改内存的配置,直接运行作业(Per Job > > 模式,下面的都是这种模式),作业能够启动起来,能正常运行,内存分配是 Flink 自己分配的; > > > > 第二种情况是配置文件指定 taskmanager.memory.managed.size > > 和 taskmanager.memory.task.heap.size 参数的大小,分别是 1024m 和 > > 256m,作业也能够正常启动运行,截图如下: > > > > http://zhisheng-blog.oss-cn-hangzhou.aliyuncs.com/2020-03-10-031628.png > > > > 第三种情况是启动的时候通过参数(-ytm 4096m)指定 TM > > 整个的内存,这种情况我没有修改配置文件的内存分配,也是能够正常运行的,截图如下图所示,这些内存分配应该是根据计算公式算出来的大小 > > > > http://zhisheng-blog.oss-cn-hangzhou.aliyuncs.com/2020-03-10-031745.png > > > > 第四种情况是启动的时候通过参数(-ytm 4096m)指定 TM 整个的内存,这种情况我自己指定了 > > taskmanager.memory.managed.size 和 taskmanager.memory.task.heap.size > > 参数的大小,发现启动作业报异常, > > > > Caused by: org.apache.flink.configuration.IllegalConfigurationException: > > Derived JVM Overhead size (2.236gb (2400539987 bytes)) is not in > configured > > JVM Overhead range [192.000mb (201326592 bytes), 1024.000mb (1073741824 > > bytes)] > > > > http://zhisheng-blog.oss-cn-hangzhou.aliyuncs.com/2020-03-10-032045.png > > > > 个人觉得原因可能是因为我指定了taskmanager.memory.managed.size > > 和 taskmanager.memory.task.heap.size 参数的大小,Flink 就将 4096m > > 减去指定的大小,然后将剩下来的分配给其他的几种内存,结果超出了 Overhead 的默认最大值,所以检查就返回异常了,不知道是不是这样的原理? > > > > 那么就有个问题了,因为在生产环境其实很难知道所有作业的运行状态,所以我们都是这边都是通过 参数(-ytm 4096m)指定 TM > > 的内存,如果不指定是使用默认的,那么如果和上面情况四一样,既改了配置文件中的配置,又想通过参数(-ytm)去控制整个 TM 的内存,就有冲突了? > > > > 对于这种情况,我觉得是不是可以多加个参数控制,这个参数的作用是 heap 内存的 fraction,这样我只需要根据我配置的 fraction > > 来分配总的内存值,因为我看 managed 和 network、overhead 这些都是有这个参数的 > > > > eg: > > taskmanager.memory.task.heap.fraction > > > > 不清楚这个建议是否得当,感谢! > > > > Xintong Song <[hidden email]> 于2020年3月10日周二 上午10:39写道: > > > > > > > > > > > 这里的“所配置的direct内存”,是指按照task.manager.network.memory.fraction计算得到的network > > > > memory大小。我想是不是这部分内存按照memory segment全部预分配了,所有metrics里显示的是全部是被Used了? > > > > > > > > > 是的,Network Buffer Pool 是在 TM 初始化时预申请好的。在所有内存类型中,只有 Network Memory > > > 是预申请的。Managed Memory 1.9 以前是有一个配置可以预申请(默认不开),1.10 起不再支持预申请。 > > > > > > > > > Thank you~ > > > > > > Xintong Song > > > > > > > > > > > > On Tue, Mar 10, 2020 at 10:30 AM pkuvisdudu <[hidden email]> > > wrote: > > > > > > > 多谢解答。 > > > > 关于“第二个是我看到metrics里directMemoryUsed总是和所配置的direct内存大小是一样的,不知道具体原因是啥?” > > > > > 这里的“所配置的direct内存”,是指按照task.manager.network.memory.fraction计算得到的network > > > > memory大小。我想是不是这部分内存按照memory segment全部预分配了,所有metrics里显示的是全部是被Used了? > > > > > > > > > > > > > > > > > > > > | | > > > > 张江 > > > > | > > > > | > > > > 邮箱:[hidden email] > > > > | > > > > > > > > 签名由 网易邮箱大师 定制 > > > > > > > > 在2020年03月10日 10:16,zhisheng 写道: > > > > hi,xintong,感谢耐心且专业的回答👍 > > > > > > > > Xintong Song <[hidden email]> 于2020年3月10日周二 上午10:04写道: > > > > > > > > > Hi Zhisheng, > > > > > > > > > > 1、Non-Heap 那个 UI 上展示的是否是 MetaSpace 和 Overhead 加起来的值? > > > > > > > > > > > > > > > 从物理含义上来说,Non-Heap 描述的内存开销是包含在 Metaspace + Overhead 里的。 > > > > > > > > > > > > > > > > 2、为什么本地起的 Standalone Flink,为啥 UI 上展示的 Heap 会超过设置的 > > > > > > taskmanager.memory.process.size 的值? > > > > > > > > > > > > > > > 这主要是因为,我们只针对 Metaspace 设置了 JVM 的参数,对于其他 Overhead 并没有设置 JVM > > 的参数,也并不是所有的 > > > > > Overhead 都有参数可以控制(比如栈空间)。 > > > > > > > > > > Non-Heap Max 是 JVM 自己决定的,所以通常会比 Flink 配置的 Metaspace + Overhead > > > > > 要大。可以这样理解,Flink 将整个 TM 的内存预算划分给了不同的用途,但是并不能严格保证各部分的内存都不超用,只能是 Best > > > > > Effort。其中,Managed、Network、Metaspace 是严格限制的,Off-Heap、Overhead > > > > > 是不能完全严格限制的,Heap 整体是严格限制的但是 Task/Framework 之间是非严格的。 > > > > > > > > > > Non-Heap 这个 metric 对用户的意义不大,且容易造成用户误解。FLIP-102 目前还在讨论中,我们也在给 Yadong > > > > > 提建议是否就不展示 Non-Heap了。 > > > > > > > > > > 3、默认 Flink 自身的配置下,启动 Flink 1.9 和 > > > > > > > > > > > > 1.10,运行相同的作业他们性能之间的差距大概是什么样的?如果上生产是否可以使用默认的内存配置?会不会堆内存有点小了?这个我说下我自己简单测试了下 > > > > > > Flink 1.9 和 1.10 下运行同一个有状态的作业,他们的 GC 情况差别还挺大的。1.10 Young GC > 次数差不多是 > > > 1.9 > > > > > 的两倍。 > > > > > > > > > > > > > > > 1.10 默认配置比起 1.9,减小了 Heap 增大了 Managed,可以参考 Memory Calculation Sheet > > [1] > > > 中的 > > > > > 1.9/1.10 > > > > > > > > > > > > > > > > > > > > 默认配置各部分内存大小对比(可以把这个表复制到自己的空间取得写权限,对各配置项的值进行修改可以直接看到各部分内存大小的变化)。至于对作业性能的影响,主要取决于作业类型(流还是批、statebackend类型等),没法一概而论。默认配置主要考虑的是用户初始尝试 > > > > > Flink 的需求,如果上生产的话,通常是需要改配置的。 > > > > > > > > > > > > > > > Hi 张江, > > > > > > > > > > > > > > > 一是您前面说native内存是无法知道使用情况的,那么除了cut-off里的native内存,在Flink 配置项中 > > > task/framework > > > > > > offheap(包括 direct 和 native内存)其中的native内存,以及1.10里managed > > > memory使用的native > > > > > > 内存,是不是也无法在metrics里展示使用情况? > > > > > > > > > > > > > > > Task/Framework OffHeap 也无法在 metrics 里展示。Managed Memory 理论上 Flink > > > > > 自己有统计,我们也在考虑增加相应的 metrics 展示,目前的话也还是看不到的。 > > > > > > > > > > > > > > > 第二个是我看到metrics里directMemoryUsed总是和所配置的direct内存大小是一样的,不知道具体原因是啥? > > > > > > > > > > > > > > > 要看你所说的“所配置的direct内存大小”是指什么? > > > > > > > > > > > > > > > Thank you~ > > > > > > > > > > Xintong Song > > > > > > > > > > > > > > > [1] > > > > > > > > > > > > > > > > > > > > https://docs.google.com/spreadsheets/d/1mJaMkMPfDJJ-w6nMXALYmTc4XxiV30P5U7DzgwLkSoE/edit#gid=0 > > > > > > > > > > On Tue, Mar 10, 2020 at 12:07 AM pkuvisdudu <[hidden email] > > > > > > wrote: > > > > > > > > > > > 多谢解答。 > > > > > > managed memory和network buffers在作业启动后会有调整是在 > > > > > > > > > > > > > > > > > > > > > https://ci.apache.org/projects/flink/flink-docs-release-1.9/ops/mem_setup.html > > > > > > 里看到的,是1.9版本里的。 > > > > > > > > > > > > > > > > > > > 还有两个小地方想确认一下,一是您前面说native内存是无法知道使用情况的,那么除了cut-off里的native内存,在Flink > > > 配置项中 > > > > > > task/framework offheap(包括 direct 和 > > > native内存)其中的native内存,以及1.10里managed > > > > > > memory使用的native 内存,是不是也无法在metrics里展示使用情况? > > > > > > 第二个是我看到metrics里directMemoryUsed总是和所配置的direct内存大小是一样的,不知道具体原因是啥? > > > > > > > > > > > > > > > > > > 再次非常感谢~ > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > 在 2020-03-09 18:39:13,"Xintong Song" <[hidden email]> 写道: > > > > > > >> > > > > > > >> 图1中的Direct类型里面所包含的framework offheap、task > > offheap以及shuffle就是您讲的“不在 > > > > JVM > > > > > > >> 堆上但受到 JVM 管理的内存:Direct”么? > > > > > > > > > > > > > >是的 > > > > > > > > > > > > > > > > > > > > >> 这部分内存是可以知道其使用情况并在metrics里看到的么? > > > > > > > > > > > > > >应该是与metrics中的Direct是对应的(因为绝大多数情况我们没有使用Mapped > > > > Buffer),这里细节我记不太清楚了最好再确认下。 > > > > > > > > > > > > > >另外,flink 1.10里将RocksDBStateBackend改为使用managed > > > memory,不过网页上显示的是managed > > > > > > >> memory统一使用offheap内存,您的解答里说的是native内存,不知道是不是您说的“完全不受 JVM > > > > > 管理的内存:Native”这个? > > > > > > > > > > > > > >是的 > > > > > > > > > > > > > >不是太清楚offheap和direct以及native的关系是怎样的 > > > > > > > > > > > > > >Flink 配置项中的 task/framework offheap,是包括了 direct 和 native > > > > > > >内存算在一起的,也就是说用户不需要关心具体使用的是 direct 还是 native。 > > > > > > > > > > > > > >最后,我在官网上看managed memory和network buffers在作业启动后会有变化 > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > >能把具体的页面链接发一下吗,可能指的是1.9以前的情况,1.10是不会变化的。1.9以前的话,TM会在进程启动并初始化之后触发一次GC,然后以GC后的空闲内存作为Heap内存重新算一遍managed、network内存应该多大。 > > > > > > > > > > > > > >Thank you~ > > > > > > > > > > > > > >Xintong Song > > > > > > > > > > > > > > > > > > > > > > > > > > > >On Mon, Mar 9, 2020 at 3:23 PM pkuvisdudu < > [hidden email]> > > > > > wrote: > > > > > > > > > > > > > >> 非常详细的解答,非常感谢~~ > > > > > > >> > > > > > > >> 还有一些小疑问。图1中的Direct类型里面所包含的framework offheap、task > > > > > > offheap以及shuffle就是您讲的“不在 > > > > > > >> JVM 堆上但受到 JVM 管理的内存:Direct”么?这部分内存是可以知道其使用情况并在metrics里看到的么? > > > > > > >> > > > > > > >> 另外,flink 1.10里将RocksDBStateBackend改为使用managed > > > > memory,不过网页上显示的是managed > > > > > > >> memory统一使用offheap内存,您的解答里说的是native内存,不知道是不是您说的“完全不受 JVM > > > > > > >> 管理的内存:Native”这个?不是太清楚offheap和direct以及native的关系是怎样的 > > > > > > >> > > > > > > >> 最后,我在官网上看managed memory和network > > > > > > >> buffers在作业启动后会有变化,但我一直看不懂是咋变化的,不知道这里能否解答一下 > > > > > > >> > > > > > > >> 再次感谢详细的解答~~ > > > > > > >> > > > > > > >> > > > > > > >> > > > > > > >> > > > > > > >> | | > > > > > > >> 张江 > > > > > > >> | > > > > > > >> | > > > > > > >> 邮箱:[hidden email] > > > > > > >> | > > > > > > >> > > > > > > >> 签名由 网易邮箱大师 定制 > > > > > > >> > > > > > > >> 在2020年03月09日 11:22,Xintong Song 写道: > > > > > > >> Hi, > > > > > > >> > > > > > > >> > > > > > > >> 关于你的几个问题: > > > > > > >> > > > > > > >> > > > > > > >> 1. 关于 JVM 的内存,堆内存(Heap > > > Memory)的定义通常是比较清晰的,但堆外/非堆内存(Off-Heap/Non-Heap > > > > > > >> Memory)的定义却有很多不同的版本,这应该是导致你困惑的主要原因。让我们先抛开这些名词,本质上 Java > > 应用使用的内存(不包括 > > > > JVM > > > > > > >> 自身的开销)可以分为三类: > > > > > > >> JVM 堆内存:Heap > > > > > > >> 不在 JVM 堆上但受到 JVM 管理的内存:Direct > > > > > > >> 完全不受 JVM 管理的内存:Native > > > > > > >> Direct 内存是直接映射到 JVM 虚拟机外部的内存空间,但是其用量又受到 JVM > 的管理和限制,从这个角度来讲,认为它是 > > > JVM > > > > > > 内存或者非 > > > > > > >> JVM 内存都是讲得通的。 > > > > > > >> > > > > > > >> > > > > > > >> 关于 Off-Heap/Non-Heap,广义上讲只要不是 Heap 内存就可以称为 Non-Heap,但是我们经过实验发现 > > > > MXBean > > > > > 的 > > > > > > >> Non-Heap 是不包括 Direct,而是由 Code Cache、Metaspace、Compressed Class > > > Space > > > > > > >> 几个部分组成。FLIP-102 讨论的是 metrics 如何在 WebUI 上展示,Flink metrics 是通过 > > > MXBean > > > > > > >> 获取的,因此图一展示的 Non-Heap 是与 MXBean 的 Non-Heap 定义的。 > > > > > > >> > > > > > > >> > > > > > > >> 2. Heap/Non-Heap 前面已经介绍过,而 Direct/Mapped 则同样是通过 MXBean 统计两个 > > Buffer > > > > > Pool > > > > > > >> 的情况。这里的 Direct 指的是 Direct Buffer Pool 而不是 Direct Memory,这两个 > > Buffer > > > > > Pool > > > > > > 都是受 > > > > > > >> -XX:MaxDirectMemorySize 控制的,可以认为都是 Direct Memory 的一部分。 > > > > > > >> > > > > > > >> > > > > > > >> 这几个 metrics 加在一起不是 TM 的总内存,一方面是因为 Native 内存没有被算进去(也就是 Cut-off > > > > > 的主要部分),因为 > > > > > > >> Native 是不受 JVM 管理的,MXBean 完全不知道它的使用情况。另一方面,JVM > > > > > > 自身的开销也并不是都被覆盖到了,比如对于栈空间,JVM > > > > > > >> 只能限制每个线程的栈空间有多大,但是不能限制线程的数量,因此总的栈空间大小也是不受控制的,也没有通过 Metric 来体现。 > > > > > > >> > > > > > > >> > > > > > > >> 总的来说,JVM 的内存机制是非常复杂的,且并不是每一个部分都能够由用户参数控制的。Flink 1.10 > > > > > > >> 简化了内存模型,目的是让用户不需要去关心这其中的细节,只关注 Flink 各功能模块所需的相关内存大小即可。而目前在 > 1.10 > > 中的 > > > > > > metric > > > > > > >> 是比较缺失的无法完全描述 Flink 的内存使用情况,社区提出 FLIP-102 梳理 metrics 及 UI > > > > > > >> 展示也正是为了解决这个问题。但即便如此,受 JVM 内存机制本身的限制,恐怕也很难做到每个部分都完全匹配到对应的 > metrics > > > 上。 > > > > > > >> > > > > > > >> > > > > > > >> 3. 这个应该是存在 state 里的,具体用哪种类型的内存取决于你的 State Backend > > > > > > >> 类型。MemoryStateBackend/FsStateBackend 用的是 Heap > > > 内存,RocksDBStateBackend > > > > > 用的是 > > > > > > >> Native 内存,也就是 1.10 中的 Manage Memory。 > > > > > > >> > > > > > > >> > > > > > > >> > > > > > > >> Thank you~ > > > > > > >> > > > > > > >> Xintong Song > > > > > > >> > > > > > > >> > > > > > > >> > > > > > > >> > > > > > > >> > > > > > > >> On Sun, Mar 8, 2020 at 4:49 PM pkuvisdudu < > > [hidden email]> > > > > > > wrote: > > > > > > >> > > > > > > >> Hi all, > > > > > > >> > > > > > > >> > > > > > > >> 我是Flink新人,最近在看一些flink资源管理机制的知识,有3个内存类型方面的问题想请教大家: > > > > > > >> > > > > > > >> > > > > > > >> 1. > > > > > > >> > > > > > > > > > > > > > > > > > > > > > Flink的内存类型如下图1所示,其中Heap内存和NonHeap内存由JVM管理,我想问一下Direct内存是否也是由JVM管理?因为我同时也看到过图2所示的内存类型,上面标示的是JVM > > > > > > >> Direct,但在FLIP102里看到的是属于Outside > > JVM,所以现在有点困惑。另外,我从相关页面上只看到了Network > > > > > > buffers, > > > > > > >> Managed memory, > > > Heap的计算方法,但不知道按照图1所示的内存类型,Direct内存和NonHeap是怎么计算分配的? > > > > > > >> 图1 > > > > > > >> 图2 > > > > > > >> 2. Flink metrics里展示的内存方面的信息以Status.JVM.Memory为前缀,包含Heap, > > NonHeap, > > > > > > Direct, > > > > > > >> > > > > > > > > > > > > > > > > > > > > > Mapped四种。我测试过,这四种内存Used之和应该并不是TM真正所使用的总内存。那么TM使用的总内存还包括哪些,是在哪里用到的?(不知道是不是cut-off那部分使用的内存?)Flink > > > > > > >> 1.10似乎对内存进行了更细致的划分和分配,但在metrics里展示的内配置和使用信息还是跟1.9一样的么? > > > > > > >> 3. > > > Window相关的算子会将窗口内的数据作为状态保存在内存里,等待窗口触发再进行计算。想问一下这里的状态是存在哪种类型的内存里面? > > > > > > >> > > > > > > >> > > > > > > >> 祝好, > > > > > > >> > > > > > > >> > > > > > > >> > > > > > > >> > > > > > > >> > > > > > > > > > > > > > > > > > > > > > |
«
Return to Apache Flink 中文用户邮件列表
|
1 view|%1 views
| Free forum by Nabble | Edit this page |