checkpoint 文件夹Chk-no 下面文件个数是能计算出来的吗?

Reply |
Threaded

Open this post in threaded view
|
More ♦
♦
| Loading... |
| Reply to author |
| Edit post |
| Move post |
| Delete this post |
| Delete this post and replies |
| Change post date |
| Print post |
| Permalink |
| Raw mail |
checkpoint 文件夹Chk-no 下面文件个数是能计算出来的吗?

11 posts
|
 state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/1e95606a-8f70-4876-ad6f-95e5cc38af86 state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/2a012214-734a-4c2b-804b-d96f4f3dddf8 state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/31871f64-7034-4323-9a2e-5e387e61b7c4 state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/54c12a36-c121-4fa0-be76-7996946b4beb state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/63a22932-4bce-4531-bc65-a74d403efb91 state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/64b10d96-8333-4a7e-87d1-8afe24c7d2df state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/66290710-e619-4ccf-90b6-5f09f89354f8 state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/_metadata QA1: chk文件下面的文件个数是跟operator个数并行度有关系吗?我只了解到_metadata文件是用来恢复状态的,那么其他文件代表的是什么意思呢? QA2: 可以将这些文件合并在一起吗? |
Reply |
Threaded
Open this post in threaded view
|
More ♦
♦
| Loading... |
| Reply to author |
| Edit post |
| Move post |
| Delete this post |
| Delete this post and replies |
| Change post date |
| Print post |
| Permalink |
| Raw mail |
Re: checkpoint 文件夹Chk-no 下面文件个数是能计算出来的吗?
|
166 posts
|
Hi
A1: chk-x文件下面的文件个数是跟operator个数并行度是有关系的,主要是operator state的文件。对于checkpoint场景,_metadata只是元数据,真实的operator数据都是在其他文件内。
A2: 不可以将这些文件合并在一起。因为_metadata内主要记录了文件路径,如果合并的话,找不到原始路径会有问题,无法从checkpoint进行restore
祝好
唐云
From: 陈冬林 <[hidden email]>
Sent: Thursday, July 18, 2019 15:21 To: [hidden email] <[hidden email]> Subject: checkpoint 文件夹Chk-no 下面文件个数是能计算出来的吗?
state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/1e95606a-8f70-4876-ad6f-95e5cc38af86
state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/2a012214-734a-4c2b-804b-d96f4f3dddf8
state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/31871f64-7034-4323-9a2e-5e387e61b7c4
state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/54c12a36-c121-4fa0-be76-7996946b4beb
state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/63a22932-4bce-4531-bc65-a74d403efb91
state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/64b10d96-8333-4a7e-87d1-8afe24c7d2df
state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/66290710-e619-4ccf-90b6-5f09f89354f8
state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/_metadata
QA1: chk文件下面的文件个数是跟operator个数并行度有关系吗?我只了解到_metadata文件是用来恢复状态的,那么其他文件代表的是什么意思呢?
QA2: 可以将这些文件合并在一起吗?
|
Reply |
Threaded
Open this post in threaded view
|
More ♦
♦
| Loading... |
| Reply to author |
| Edit post |
| Move post |
| Delete this post |
| Delete this post and replies |
| Change post date |
| Print post |
| Permalink |
| Raw mail |
Fwd: checkpoint 文件夹Chk-no 下面文件个数是能计算出来的吗?
|
11 posts
|
谢谢您的解答,
那些文件的数量是只和operator的并行度相关吗?是不是还有key 的个数等相关?有没有具体的公式呢?我没有在源码里找到这块的逻辑 还有一个最重要的问题,这些文件即然不能合并,state小文件合并指的是那些文件呢? 祝安 Andrew > 下面是被转发的邮件: > > 发件人: Yun Tang <[hidden email]> > 主题: 回复: checkpoint 文件夹Chk-no 下面文件个数是能计算出来的吗? > 日期: 2019年7月18日 GMT+8 下午3:24:57 > 收件人: "[hidden email]" <[hidden email]> > 回复-收件人: [hidden email] > > Hi > > A1: chk-x文件下面的文件个数是跟operator个数并行度是有关系的,主要是operator state的文件。对于checkpoint场景,_metadata只是元数据,真实的operator数据都是在其他文件内。 > > A2: 不可以将这些文件合并在一起。因为_metadata内主要记录了文件路径,如果合并的话,找不到原始路径会有问题,无法从checkpoint进行restore > > 祝好 > 唐云 > From: 陈冬林 <[hidden email]> > Sent: Thursday, July 18, 2019 15:21 > To: [hidden email] <[hidden email]> > Subject: checkpoint 文件夹Chk-no 下面文件个数是能计算出来的吗? > > > > state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/1e95606a-8f70-4876-ad6f-95e5cc38af86 > state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/2a012214-734a-4c2b-804b-d96f4f3dddf8 > state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/31871f64-7034-4323-9a2e-5e387e61b7c4 > state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/54c12a36-c121-4fa0-be76-7996946b4beb > state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/63a22932-4bce-4531-bc65-a74d403efb91 > state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/64b10d96-8333-4a7e-87d1-8afe24c7d2df > state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/66290710-e619-4ccf-90b6-5f09f89354f8 > state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/_metadata > > QA1: chk文件下面的文件个数是跟operator个数并行度有关系吗?我只了解到_metadata文件是用来恢复状态的,那么其他文件代表的是什么意思呢? > > QA2: 可以将这些文件合并在一起吗? ... [show rest of quote] |
Reply |
Threaded
Open this post in threaded view
|
More ♦
♦
| Loading... |
| Reply to author |
| Edit post |
| Move post |
| Delete this post |
| Delete this post and replies |
| Change post date |
| Print post |
| Permalink |
| Raw mail |
Re: checkpoint 文件夹Chk-no 下面文件个数是能计算出来的吗?
|
166 posts
|
Hi
源码部分可以参考[1] DefaultOperatorStateBackendSnapshotStrategy 执行完成的时候,每个operator state backend 都只会产生至多一个文件。 state小文件合并,你指的应该是FLINK-11937<https://issues.apache.org/jira/browse/FLINK-11937> 吧,这里的所谓合并是每个rocksDB state backend创建checkpoint的时候,在一定阈值内,若干sst文件的序列化结果都写到一个文件内。由于keyed state体积比较大,每次checkpoint时候,创建的文件数目一般不止一个。 [1] https://github.com/apache/flink/blob/1ec34249a0303ae64d049d177057ef9b6c413ab5/flink-runtime/src/main/java/org/apache/flink/runtime/state/DefaultOperatorStateBackendSnapshotStrategy.java#L179 祝好 唐云 ________________________________ From: 陈冬林 <[hidden email]> Sent: Thursday, July 18, 2019 15:34 To: [hidden email] <[hidden email]> Subject: Fwd: checkpoint 文件夹Chk-no 下面文件个数是能计算出来的吗? 谢谢您的解答, 那些文件的数量是只和operator的并行度相关吗?是不是还有key 的个数等相关?有没有具体的公式呢?我没有在源码里找到这块的逻辑 还有一个最重要的问题,这些文件即然不能合并,state小文件合并指的是那些文件呢? 祝安 Andrew > 下面是被转发的邮件: > > 发件人: Yun Tang <[hidden email]> > 主题: 回复: checkpoint 文件夹Chk-no 下面文件个数是能计算出来的吗? > 日期: 2019年7月18日 GMT+8 下午3:24:57 > 收件人: "[hidden email]" <[hidden email]> > 回复-收件人: [hidden email] > > Hi > > A1: chk-x文件下面的文件个数是跟operator个数并行度是有关系的,主要是operator state的文件。对于checkpoint场景,_metadata只是元数据,真实的operator数据都是在其他文件内。 > > A2: 不可以将这些文件合并在一起。因为_metadata内主要记录了文件路径,如果合并的话,找不到原始路径会有问题,无法从checkpoint进行restore > > 祝好 > 唐云 > From: 陈冬林 <[hidden email]> > Sent: Thursday, July 18, 2019 15:21 > To: [hidden email] <[hidden email]> > Subject: checkpoint 文件夹Chk-no 下面文件个数是能计算出来的吗? > > > > state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/1e95606a-8f70-4876-ad6f-95e5cc38af86 > state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/2a012214-734a-4c2b-804b-d96f4f3dddf8 > state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/31871f64-7034-4323-9a2e-5e387e61b7c4 > state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/54c12a36-c121-4fa0-be76-7996946b4beb > state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/63a22932-4bce-4531-bc65-a74d403efb91 > state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/64b10d96-8333-4a7e-87d1-8afe24c7d2df > state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/66290710-e619-4ccf-90b6-5f09f89354f8 > state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/_metadata > > QA1: chk文件下面的文件个数是跟operator个数并行度有关系吗?我只了解到_metadata文件是用来恢复状态的,那么其他文件代表的是什么意思呢? > > QA2: 可以将这些文件合并在一起吗? ... [show rest of quote] |
Reply |
Threaded
Open this post in threaded view
|
More ♦
♦
| Loading... |
| Reply to author |
| Edit post |
| Move post |
| Delete this post |
| Delete this post and replies |
| Change post date |
| Print post |
| Permalink |
| Raw mail |
Fwd: checkpoint 文件夹Chk-no 下面文件个数是能计算出来的吗?
|
11 posts
|
好的,非常感谢您的解答。 > 下面是被转发的邮件: > > 发件人: Yun Tang <[hidden email]> > 主题: 回复: checkpoint 文件夹Chk-no 下面文件个数是能计算出来的吗? > 日期: 2019年7月18日 GMT+8 下午4:06:59 > 收件人: "[hidden email]" <[hidden email]> > 回复-收件人: [hidden email] > > Hi > > 源码部分可以参考[1] DefaultOperatorStateBackendSnapshotStrategy 执行完成的时候,每个operator state backend 都只会产生至多一个文件。 > > state小文件合并,你指的应该是FLINK-11937<https://issues.apache.org/jira/browse/FLINK-11937> 吧,这里的所谓合并是每个rocksDB state backend创建checkpoint的时候,在一定阈值内,若干sst文件的序列化结果都写到一个文件内。由于keyed state体积比较大,每次checkpoint时候,创建的文件数目一般不止一个。 > > > [1] https://github.com/apache/flink/blob/1ec34249a0303ae64d049d177057ef9b6c413ab5/flink-runtime/src/main/java/org/apache/flink/runtime/state/DefaultOperatorStateBackendSnapshotStrategy.java#L179 > > 祝好 > 唐云 > > > ________________________________ > From: 陈冬林 <[hidden email]> > Sent: Thursday, July 18, 2019 15:34 > To: [hidden email] <[hidden email]> > Subject: Fwd: checkpoint 文件夹Chk-no 下面文件个数是能计算出来的吗? > > 谢谢您的解答, > 那些文件的数量是只和operator的并行度相关吗?是不是还有key 的个数等相关?有没有具体的公式呢?我没有在源码里找到这块的逻辑 > > 还有一个最重要的问题,这些文件即然不能合并,state小文件合并指的是那些文件呢? > > > 祝安 > Andrew > > >> 下面是被转发的邮件: >> >> 发件人: Yun Tang <[hidden email]> >> 主题: 回复: checkpoint 文件夹Chk-no 下面文件个数是能计算出来的吗? >> 日期: 2019年7月18日 GMT+8 下午3:24:57 >> 收件人: "[hidden email]" <[hidden email]> >> 回复-收件人: [hidden email] >> >> Hi >> >> A1: chk-x文件下面的文件个数是跟operator个数并行度是有关系的,主要是operator state的文件。对于checkpoint场景,_metadata只是元数据,真实的operator数据都是在其他文件内。 >> >> A2: 不可以将这些文件合并在一起。因为_metadata内主要记录了文件路径,如果合并的话,找不到原始路径会有问题,无法从checkpoint进行restore >> >> 祝好 >> 唐云 >> From: 陈冬林 <[hidden email]> >> Sent: Thursday, July 18, 2019 15:21 >> To: [hidden email] <[hidden email]> >> Subject: checkpoint 文件夹Chk-no 下面文件个数是能计算出来的吗? >> >> >> >> state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/1e95606a-8f70-4876-ad6f-95e5cc38af86 >> state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/2a012214-734a-4c2b-804b-d96f4f3dddf8 >> state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/31871f64-7034-4323-9a2e-5e387e61b7c4 >> state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/54c12a36-c121-4fa0-be76-7996946b4beb >> state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/63a22932-4bce-4531-bc65-a74d403efb91 >> state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/64b10d96-8333-4a7e-87d1-8afe24c7d2df >> state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/66290710-e619-4ccf-90b6-5f09f89354f8 >> state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/_metadata >> >> QA1: chk文件下面的文件个数是跟operator个数并行度有关系吗?我只了解到_metadata文件是用来恢复状态的,那么其他文件代表的是什么意思呢? >> >> QA2: 可以将这些文件合并在一起吗? > ... [show rest of quote] |
Reply |
Threaded
Open this post in threaded view
|
More ♦
♦
| Loading... |
| Reply to author |
| Edit post |
| Move post |
| Delete this post |
| Delete this post and replies |
| Change post date |
| Print post |
| Permalink |
| Raw mail |
Fwd: checkpoint 文件夹Chk-no 下面文件个数是能计算出来的吗?
|
11 posts
|
In reply to this post by AndrwLin
唐云老师您好; 基于hdfs的backend 可以优化checkpoint小文件的数量吗?减少namenode压力吗?
现状是会影响namenode rpc响应设计 gc频繁,内存占用过高。
... [show rest of quote] |

Reply |
Threaded
Open this post in threaded view
|
More ♦
♦
| Loading... |
| Reply to author |
| Edit post |
| Move post |
| Delete this post |
| Delete this post and replies |
| Change post date |
| Print post |
| Permalink |
| Raw mail |
Re: checkpoint 文件夹Chk-no 下面文件个数是能计算出来的吗?
|
166 posts
|
hi
首先先要确定是否是大量创造文件导致你的namenode RPC相应堆积多,RPC请求有很多种,例如每个task创建checkpoint目录也是会向namenode发送大量RPC请求的(参见 [https://issues.apache.org/jira/browse/FLINK-11696]);也有可能是你的checkpoint interval太小,导致文件不断被创建和删除(subsume
old checkpoint),先找到NN压力大的root cause吧。
至于使用FsStateBackend能否减少checkpoint文件数量,这是另外一个话题。首先,我需要弄清楚你目前使用的是什么state backend,如果目前是MemoryStateBackend,由于该state backend对应的keyed state backend并不会在checkpoint时候创建任何文件,反而在文件数目上来看是对NN压力最小的(相比于FsStateBackend来说要更好)。还有你作业的并发度是多少,每个checkpoint目录下的文件数目又是多少。降低并发度是一种减少文件数目的办法。当然,我觉得如果你只是使用MemoryStateBackend就足够handle
checkpoint size的话,不应该会触及文件数目太多的问题,除非你的checkpoint间隔实在太小了。
祝好
唐云
From: 陈冬林 <[hidden email]>
Sent: Thursday, July 18, 2019 17:49 To: [hidden email] <[hidden email]> Cc: [hidden email] <[hidden email]> Subject: Fwd: checkpoint 文件夹Chk-no 下面文件个数是能计算出来的吗? 唐云老师您好; 基于hdfs的backend 可以优化checkpoint小文件的数量吗?减少namenode压力吗?
现状是会影响namenode rpc响应设计 gc频繁,内存占用过高。
... [show rest of quote]
|
Reply |
Threaded
Open this post in threaded view
|
More ♦
♦
| Loading... |
| Reply to author |
| Edit post |
| Move post |
| Delete this post |
| Delete this post and replies |
| Change post date |
| Print post |
| Permalink |
| Raw mail |
Re: checkpoint 文件夹Chk-no 下面文件个数是能计算出来的吗?
|
11 posts
|
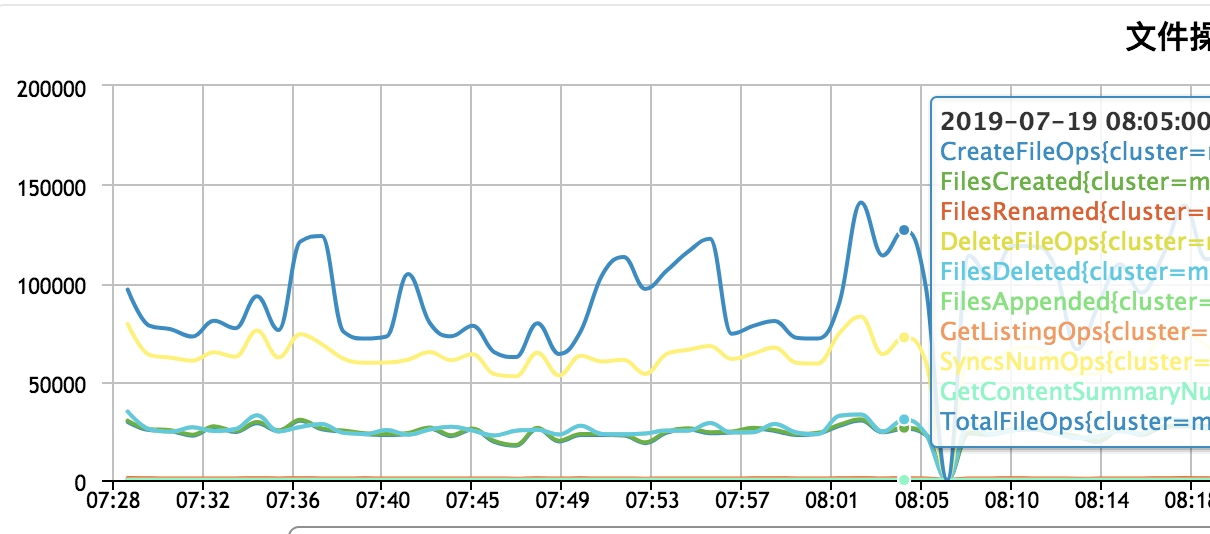 您好! 我觉得您分析的很有道理,集群 createFile和deleteFile 调用请求是最多的。 我们的小集群上跑了近百个flink任务,使用FsStateBackend 存储到hdfs上。checkpoint interval不是我们能决定的。 有没有其他方面可以减少namenode的压力,我看了您github上的代码,是个很不错的优化点,可以考虑实践一下,请问线上验证过吗,我稍后再学习一下您的代码?
请问这个话题有没有什么优化点可以启发一下吗?
... [show rest of quote] |
Reply |
Threaded
Open this post in threaded view
|
More ♦
♦
| Loading... |
| Reply to author |
| Edit post |
| Move post |
| Delete this post |
| Delete this post and replies |
| Change post date |
| Print post |
| Permalink |
| Raw mail |
Re: checkpoint 文件夹Chk-no 下面文件个数是能计算出来的吗?
|
166 posts
|
Hi
[https://issues.apache.org/jira/browse/FLINK-11696] 里面目前的PR是我们的生产代码,你可以用。但是你现在的问题的root cause不是这个,而是创建文件和删除文件的请求太多了。可以统计一下目前你们几百个作业的checkpoint interval,一般而言3~5min的间隔就完全足够了,没必要将interval调整得太小,这是一个影响你们整个集群使用的配置,必要时需要告知用户正确的配置。
如果你们使用FsStateBackend,在目前的Flink场景下,已经是创建文件数目最优的选项了。剩下能做的优化就是降低不必要的并发度还有就是调大 state.backend.fs.memory-threshold 参数(默认值是1KB,最大值是1MB),但是这个参数会有一个副作用,可能需要同时调大jobmanager的heap大小。
祝好
唐云
From: 陈冬林 <[hidden email]>
Sent: Friday, July 19, 2019 9:45 To: [hidden email] <[hidden email]> Subject: Re: checkpoint 文件夹Chk-no 下面文件个数是能计算出来的吗? 您好!
我觉得您分析的很有道理,集群 createFile和deleteFile 调用请求是最多的。
我们的小集群上跑了近百个flink任务,使用FsStateBackend 存储到hdfs上。checkpoint interval不是我们能决定的。
有没有其他方面可以减少namenode的压力,我看了您github上的代码,是个很不错的优化点,可以考虑实践一下,请问线上验证过吗,我稍后再学习一下您的代码?
请问这个话题有没有什么优化点可以启发一下吗?
... [show rest of quote]
|
Reply |
Threaded
Open this post in threaded view
|
More ♦
♦
| Loading... |
| Reply to author |
| Edit post |
| Move post |
| Delete this post |
| Delete this post and replies |
| Change post date |
| Print post |
| Permalink |
| Raw mail |
Fwd: checkpoint 文件夹Chk-no 下面文件个数是能计算出来的吗?
|
11 posts
|
谢谢您的回复,您的每一次解答都让我受益;
Infoq这片文章( https://www.infoq.cn/article/EE2bAVOOWa0K_g5lLh7j <https://www.infoq.cn/article/EE2bAVOOWa0K_g5lLh7j>)介绍阿里合并小文件成一个大文件,减少NN的压力, 指的是这个PR(https://issues.apache.org/jira/browse/FLINK-11937 <https://issues.apache.org/jira/browse/FLINK-11937>)的策略吗?还是另有所指? “Checkpoint 小文件合并:都是规模惹的祸,随着整个集群 Flink JOB 越来越多,CP 文件数也水涨船高,最后压的 HDFS NameNode 不堪重负,阿里巴巴通过把若干 CP 小文件合并成一个大文件的组织方式,最终把 NameNode 的压力减少了几十倍 ” > 下面是被转发的邮件: > > 发件人: Yun Tang <[hidden email]> > 主题: 回复: checkpoint 文件夹Chk-no 下面文件个数是能计算出来的吗? > 日期: 2019年7月19日 GMT+8 上午11:05:53 > 收件人: "[hidden email]" <[hidden email]> > 回复-收件人: [hidden email] > > Hi > > [https://issues.apache.org/jira/browse/FLINK-11696 <https://issues.apache.org/jira/browse/FLINK-11696>] 里面目前的PR是我们的生产代码,你可以用。但是你现在的问题的root cause不是这个,而是创建文件和删除文件的请求太多了。可以统计一下目前你们几百个作业的checkpoint interval,一般而言3~5min的间隔就完全足够了,没必要将interval调整得太小,这是一个影响你们整个集群使用的配置,必要时需要告知用户正确的配置。 > > 如果你们使用FsStateBackend,在目前的Flink场景下,已经是创建文件数目最优的选项了。剩下能做的优化就是降低不必要的并发度还有就是调大 state.backend.fs.memory-threshold 参数(默认值是1KB,最大值是1MB),但是这个参数会有一个副作用,可能需要同时调大jobmanager的heap大小。 > > 祝好 > 唐云 > From: 陈冬林 <[hidden email]> > Sent: Friday, July 19, 2019 9:45 > To: [hidden email] <[hidden email]> > Subject: Re: checkpoint 文件夹Chk-no 下面文件个数是能计算出来的吗? > > > > > 您好! > 我觉得您分析的很有道理,集群 createFile和deleteFile 调用请求是最多的。 > > 我们的小集群上跑了近百个flink任务,使用FsStateBackend 存储到hdfs上。checkpoint interval不是我们能决定的。 > 有没有其他方面可以减少namenode的压力,我看了您github上的代码,是个很不错的优化点,可以考虑实践一下,请问线上验证过吗,我稍后再学习一下您的代码? > >> 至于使用FsStateBackend能否减少checkpoint文件数量,这是另外一个话题 > > 请问这个话题有没有什么优化点可以启发一下吗? > > > > >> 在 2019年7月18日,下午9:34,Yun Tang <[hidden email] <mailto:[hidden email]>> 写道: >> >> hi >> >> 首先先要确定是否是大量创造文件导致你的namenode RPC相应堆积多,RPC请求有很多种,例如每个task创建checkpoint目录也是会向namenode发送大量RPC请求的(参见 [https://issues.apache.org/jira/browse/FLINK-11696 <https://issues.apache.org/jira/browse/FLINK-11696>]);也有可能是你的checkpoint interval太小,导致文件不断被创建和删除(subsume old checkpoint),先找到NN压力大的root cause吧。 >> >> 至于使用FsStateBackend能否减少checkpoint文件数量,这是另外一个话题。首先,我需要弄清楚你目前使用的是什么state backend,如果目前是MemoryStateBackend,由于该state backend对应的keyed state backend并不会在checkpoint时候创建任何文件,反而在文件数目上来看是对NN压力最小的(相比于FsStateBackend来说要更好)。还有你作业的并发度是多少,每个checkpoint目录下的文件数目又是多少。降低并发度是一种减少文件数目的办法。当然,我觉得如果你只是使用MemoryStateBackend就足够handle checkpoint size的话,不应该会触及文件数目太多的问题,除非你的checkpoint间隔实在太小了。 >> >> 祝好 >> 唐云 >> From: 陈冬林 <[hidden email] <mailto:[hidden email]>> >> Sent: Thursday, July 18, 2019 17:49 >> To: [hidden email] <mailto:[hidden email]> <[hidden email] <mailto:[hidden email]>> >> Cc: [hidden email] <mailto:[hidden email]> <[hidden email] <mailto:[hidden email]>> >> Subject: Fwd: checkpoint 文件夹Chk-no 下面文件个数是能计算出来的吗? >> >> >> 唐云老师您好; >> 基于hdfs的backend 可以优化checkpoint小文件的数量吗?减少namenode压力吗? >> 现状是会影响namenode rpc响应设计 gc频繁,内存占用过高。 >> >>> 下面是被转发的邮件: >>> >>> 发件人: 陈冬林 <[hidden email] <mailto:[hidden email]>> >>> 主题: checkpoint 文件夹Chk-no 下面文件个数是能计算出来的吗? >>> 日期: 2019年7月18日 GMT+8 下午3:21:12 >>> 收件人: [hidden email] <mailto:[hidden email]> >>> >>> >>> >>> state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/1e95606a-8f70-4876-ad6f-95e5cc38af86 >>> state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/2a012214-734a-4c2b-804b-d96f4f3dddf8 >>> state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/31871f64-7034-4323-9a2e-5e387e61b7c4 >>> state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/54c12a36-c121-4fa0-be76-7996946b4beb >>> state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/63a22932-4bce-4531-bc65-a74d403efb91 >>> state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/64b10d96-8333-4a7e-87d1-8afe24c7d2df >>> state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/66290710-e619-4ccf-90b6-5f09f89354f8 >>> state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/_metadata >>> >>> QA1: chk文件下面的文件个数是跟operator个数并行度有关系吗?我只了解到_metadata文件是用来恢复状态的,那么其他文件代表的是什么意思呢? >>> >>> QA2: 可以将这些文件合并在一起吗? ... [show rest of quote] |
Reply |
Threaded
Open this post in threaded view
|
More ♦
♦
| Loading... |
| Reply to author |
| Edit post |
| Move post |
| Delete this post |
| Delete this post and replies |
| Change post date |
| Print post |
| Permalink |
| Raw mail |
Re: checkpoint 文件夹Chk-no 下面文件个数是能计算出来的吗?
|
166 posts
|
Hi
嗯基本上对应的就是这个JIRA,不过你们的问题(FsStateBackend)其实与FLINK-11937的动机不完全匹配,归根到底还是需要考虑增大checkpoint interval。 祝好 唐云 ________________________________ From: 陈冬林 <[hidden email]> Sent: Friday, July 19, 2019 16:31 To: [hidden email] <[hidden email]> Subject: Fwd: checkpoint 文件夹Chk-no 下面文件个数是能计算出来的吗? 谢谢您的回复,您的每一次解答都让我受益; Infoq这片文章( https://www.infoq.cn/article/EE2bAVOOWa0K_g5lLh7j <https://www.infoq.cn/article/EE2bAVOOWa0K_g5lLh7j>)介绍阿里合并小文件成一个大文件,减少NN的压力, 指的是这个PR(https://issues.apache.org/jira/browse/FLINK-11937 <https://issues.apache.org/jira/browse/FLINK-11937>)的策略吗?还是另有所指? “Checkpoint 小文件合并:都是规模惹的祸,随着整个集群 Flink JOB 越来越多,CP 文件数也水涨船高,最后压的 HDFS NameNode 不堪重负,阿里巴巴通过把若干 CP 小文件合并成一个大文件的组织方式,最终把 NameNode 的压力减少了几十倍 ” > 下面是被转发的邮件: > > 发件人: Yun Tang <[hidden email]> > 主题: 回复: checkpoint 文件夹Chk-no 下面文件个数是能计算出来的吗? > 日期: 2019年7月19日 GMT+8 上午11:05:53 > 收件人: "[hidden email]" <[hidden email]> > 回复-收件人: [hidden email] > > Hi > > [https://issues.apache.org/jira/browse/FLINK-11696 <https://issues.apache.org/jira/browse/FLINK-11696>] 里面目前的PR是我们的生产代码,你可以用。但是你现在的问题的root cause不是这个,而是创建文件和删除文件的请求太多了。可以统计一下目前你们几百个作业的checkpoint interval,一般而言3~5min的间隔就完全足够了,没必要将interval调整得太小,这是一个影响你们整个集群使用的配置,必要时需要告知用户正确的配置。 > > 如果你们使用FsStateBackend,在目前的Flink场景下,已经是创建文件数目最优的选项了。剩下能做的优化就是降低不必要的并发度还有就是调大 state.backend.fs.memory-threshold 参数(默认值是1KB,最大值是1MB),但是这个参数会有一个副作用,可能需要同时调大jobmanager的heap大小。 > > 祝好 > 唐云 > From: 陈冬林 <[hidden email]> > Sent: Friday, July 19, 2019 9:45 > To: [hidden email] <[hidden email]> > Subject: Re: checkpoint 文件夹Chk-no 下面文件个数是能计算出来的吗? > > > > > 您好! > 我觉得您分析的很有道理,集群 createFile和deleteFile 调用请求是最多的。 > > 我们的小集群上跑了近百个flink任务,使用FsStateBackend 存储到hdfs上。checkpoint interval不是我们能决定的。 > 有没有其他方面可以减少namenode的压力,我看了您github上的代码,是个很不错的优化点,可以考虑实践一下,请问线上验证过吗,我稍后再学习一下您的代码? > >> 至于使用FsStateBackend能否减少checkpoint文件数量,这是另外一个话题 > > 请问这个话题有没有什么优化点可以启发一下吗? > > > > >> 在 2019年7月18日,下午9:34,Yun Tang <[hidden email] <mailto:[hidden email]>> 写道: >> >> hi >> >> 首先先要确定是否是大量创造文件导致你的namenode RPC相应堆积多,RPC请求有很多种,例如每个task创建checkpoint目录也是会向namenode发送大量RPC请求的(参见 [https://issues.apache.org/jira/browse/FLINK-11696 <https://issues.apache.org/jira/browse/FLINK-11696>]);也有可能是你的checkpoint interval太小,导致文件不断被创建和删除(subsume old checkpoint),先找到NN压力大的root cause吧。 >> >> 至于使用FsStateBackend能否减少checkpoint文件数量,这是另外一个话题。首先,我需要弄清楚你目前使用的是什么state backend,如果目前是MemoryStateBackend,由于该state backend对应的keyed state backend并不会在checkpoint时候创建任何文件,反而在文件数目上来看是对NN压力最小的(相比于FsStateBackend来说要更好)。还有你作业的并发度是多少,每个checkpoint目录下的文件数目又是多少。降低并发度是一种减少文件数目的办法。当然,我觉得如果你只是使用MemoryStateBackend就足够handle checkpoint size的话,不应该会触及文件数目太多的问题,除非你的checkpoint间隔实在太小了。 >> >> 祝好 >> 唐云 >> From: 陈冬林 <[hidden email] <mailto:[hidden email]>> >> Sent: Thursday, July 18, 2019 17:49 >> To: [hidden email] <mailto:[hidden email]> <[hidden email] <mailto:[hidden email]>> >> Cc: [hidden email] <mailto:[hidden email]> <[hidden email] <mailto:[hidden email]>> >> Subject: Fwd: checkpoint 文件夹Chk-no 下面文件个数是能计算出来的吗? >> >> >> 唐云老师您好; >> 基于hdfs的backend 可以优化checkpoint小文件的数量吗?减少namenode压力吗? >> 现状是会影响namenode rpc响应设计 gc频繁,内存占用过高。 >> >>> 下面是被转发的邮件: >>> >>> 发件人: 陈冬林 <[hidden email] <mailto:[hidden email]>> >>> 主题: checkpoint 文件夹Chk-no 下面文件个数是能计算出来的吗? >>> 日期: 2019年7月18日 GMT+8 下午3:21:12 >>> 收件人: [hidden email] <mailto:[hidden email]> >>> >>> >>> >>> state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/1e95606a-8f70-4876-ad6f-95e5cc38af86 >>> state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/2a012214-734a-4c2b-804b-d96f4f3dddf8 >>> state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/31871f64-7034-4323-9a2e-5e387e61b7c4 >>> state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/54c12a36-c121-4fa0-be76-7996946b4beb >>> state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/63a22932-4bce-4531-bc65-a74d403efb91 >>> state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/64b10d96-8333-4a7e-87d1-8afe24c7d2df >>> state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/66290710-e619-4ccf-90b6-5f09f89354f8 >>> state_checkpoints_dir/2d93ffacbddcf363b960317816566552/chk-2903/_metadata >>> >>> QA1: chk文件下面的文件个数是跟operator个数并行度有关系吗?我只了解到_metadata文件是用来恢复状态的,那么其他文件代表的是什么意思呢? >>> >>> QA2: 可以将这些文件合并在一起吗? ... [show rest of quote] |
«
Return to Apache Flink 中文用户邮件列表
|
559 views
| Free forum by Nabble | Edit this page |