各位好:
我在使用flink的过程中遇到了下面的问题,刚开始接触flink,对排查问题的思路不是很清晰,麻烦大家提供下思路哈,谢谢。
应用场景:我这里使用Standalone Cluster方式搭建了一flink集群,其中Task Managers=10,Task Slots=54。
flink的stream过程大致为: kafka topic1的数据 --> 异步调用外部资源对数据填充 --> 存入kafka topic2。
其中topic1的分区有100个,数据是平均分布的。topic2的分区有50个。
异步调用使用的flink RichAsyncFunction,无序。外部资源就是一个web服务,但是业务逻辑很复杂,处理时间比较久,平均5秒左右,使用nginx代理了多个节点进行服务。
提交任务时指定的并发度为50.
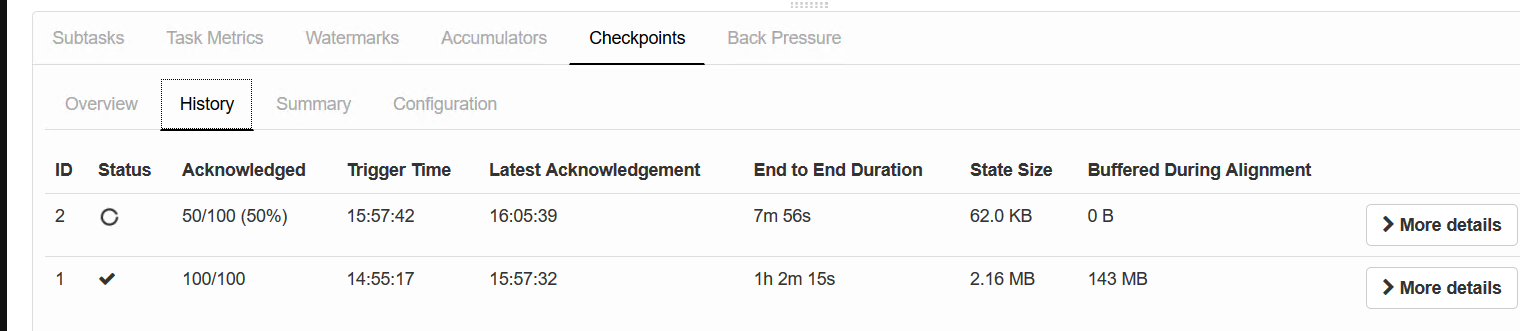
遇到的问题:checkpoint始终超时,而且执行时间非常久。使用bin/flink savepoint xxx也会超时。取消了之前的任务,将CheckpointTimeout重新设置为3小时目前成功,之前是1小时全部失败。看了其他的资料,推测是背压造成的。
checkpoint配置:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(1000 * 60 * 3); //3m
env.getCheckpointConfig().setCheckpointTimeout(1000 * 60 * 180); //3h,之前配置的1小时,都失败了,这次改为3小时。
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(1000 * 10); //间隔10s
StateBackend backend = new RocksDBStateBackend(filebackend, true); //使用RocksDBStateBackend增量
env.setStateBackend(backend);
求助:请问遇到这个问题该怎么排查呢?为什么checkpoint时间会消耗这么长,可能的原因是什么呢?查看上游背压一直是high,下游因为要调用外部web服务所以消费速度低,怎么解决这个问题呢?请各位提供下建议,谢谢哈。
web ui截图:

刚刚看了下,运行了1个多小时的checkpoint终于成功了一个。
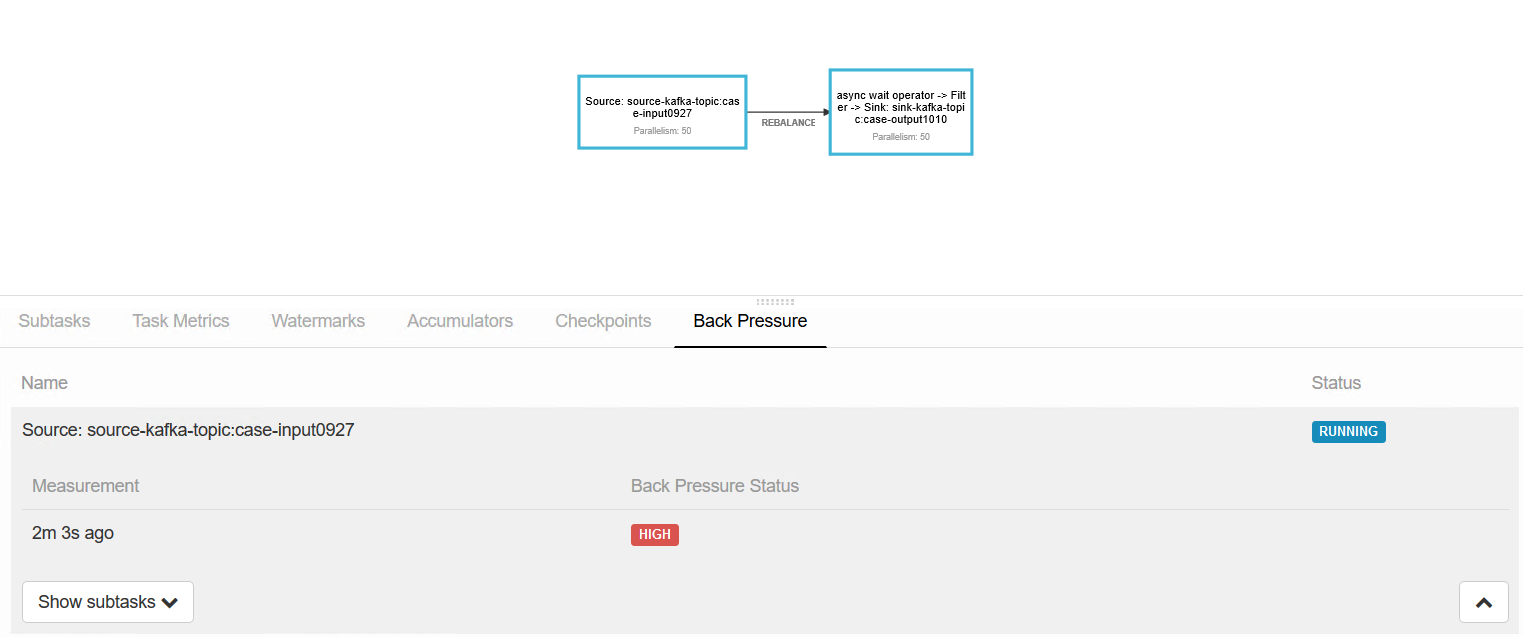
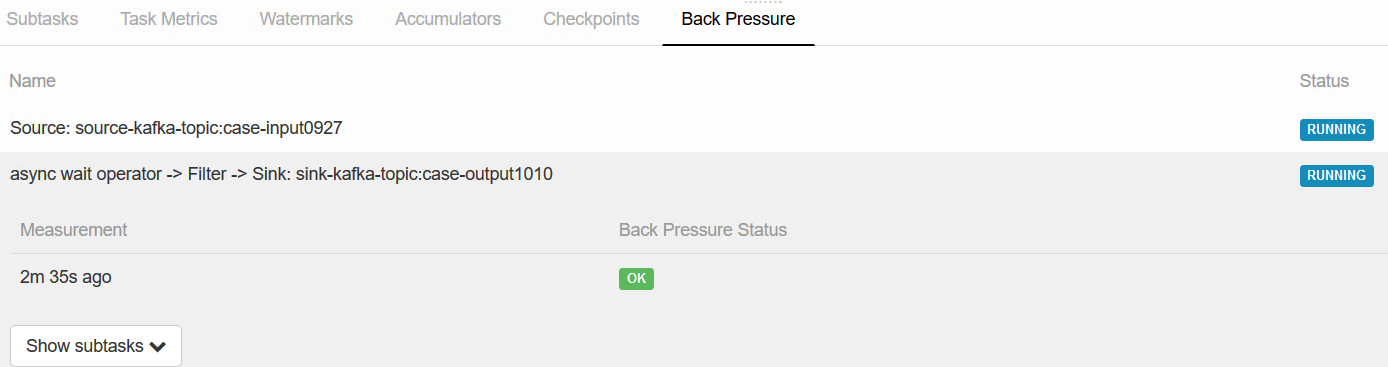
背压情况: 上游一直是high,不正常
祝各位一切顺利!

