最近在做一个报表的项目,5分钟和小时的报表采用Flink计算,遇到下面几个问题,请大佬帮忙解答下,谢谢。
输入的原始数据流包含了几十个维度和指标字段,然后会抽取其中的2~3个维度和若干指标进行汇聚计算, 有些还需要计算分组TOPN,还有任务依赖,先计算3个维度,然后从3个维度计算两个维度。
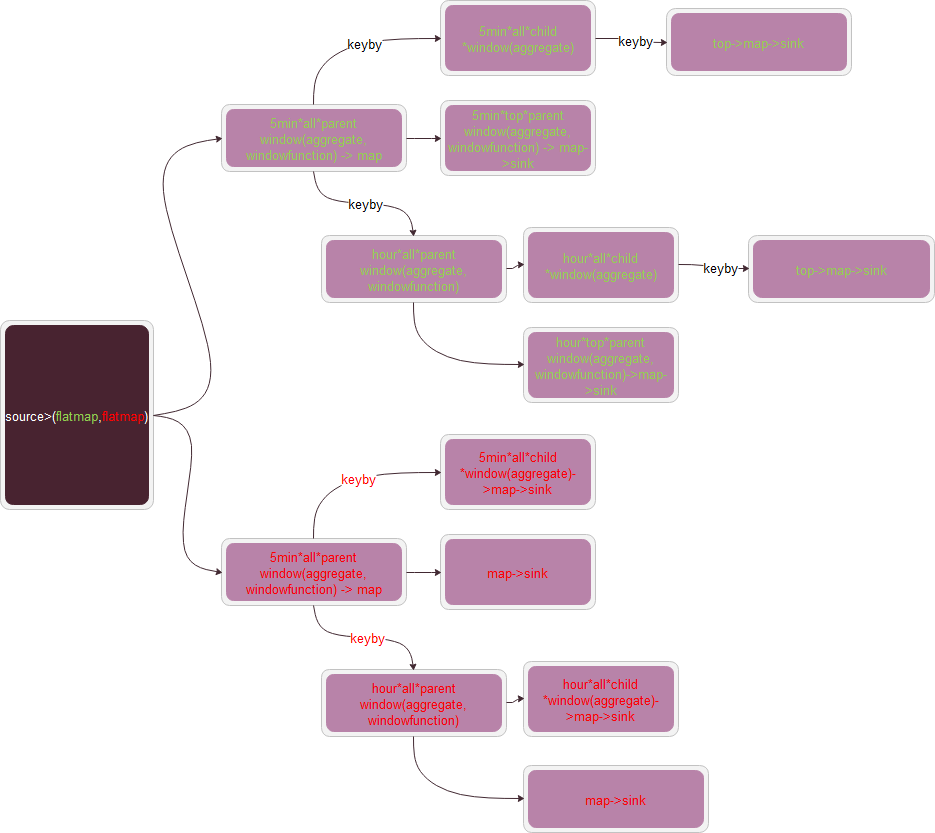
我当前的实现流图是:
中间数据都是使用Row来传递,最后将Row转换成Avro的Record写入HDFS。
现在单个时间粒度要计算近300张报表,任务图太复杂,我将计算任务分到了4个Job(1.7.2版本jobgraph过大提交不上去),每个处理两个时粒度的140张报表, 当前遇到的问题:
1、并行度是4的时候已经几百个个task。 单个taskmanager的线程数在1000~2000,线程内存消耗近2G(单个线程栈大小1MB),整体内存消耗过大,经常出现物理内存超出限制,container被杀。
2、任务提交到部署完成比较慢,默认akka.time.out是10秒时经常超时,改到60s才行。
3、checkpoint时日志打印比较多,出问题时也不好定位。
4、任务计算速率提升不上去,当前2vcore+8G内存, 2slot时,单并行度的计算能力是20000左右。
5、kafka数据消费时,partition > source的并行度,一个并行度消费多个partition的数据,没有找到kafka connector的均衡消费的配置,经常出现一个partition消费完了才去消费另一个,导致数据过了窗口+乱序等待时长从而被丢弃。
想问下,大佬有没有什么简化的计算方案推荐下。
自己试过计算过程中加上报表名称信息,然后每个算子计算所有的报表任务,最后再根据报表名称将计算好的数据写入到HDFS。计算过程中需要进行keyby时需要指定输出数据类型和字段数量,不同任务的key字段数量和类型不一样,无法指定统一的类型。