1.11 kafka producer 只往一个partition里写


|
我看1.11的kafka默认是用FlinkFixedPartitioner,应该是把sink每个subtask里的数据全部写到某一个partition吧?但是碰到了一个奇怪的事情:job整体并行度为5的情况下,数据结果只往partition 0里写。然后把partitoner用null替代之后是以roundrobin方式写入每一个partition。感到很奇怪啊。求助
发自我的iPhone 发自我的iPhone |
|
|
目前Kafka producer的partitioner使用的是org.apache.flink.streaming.connectors.kafka.partitioner.FlinkFixedPartitioner这个类
具体的分区方法是org.apache.flink.streaming.connectors.kafka.partitioner.FlinkFixedPartitioner#partition 由该方法可以得知你每个subtask发到哪个kafka的partition中。每个subtask的数据只会写到一个固定的partition里面。 ------------------ 原始邮件 ------------------ 发件人: "user-zh" <[hidden email]>; 发送时间: 2020年8月17日(星期一) 晚上10:03 收件人: "user-zh"<[hidden email]>; 主题: 1.11 kafka producer 只往一个partition里写 我看1.11的kafka默认是用FlinkFixedPartitioner,应该是把sink每个subtask里的数据全部写到某一个partition吧?但是碰到了一个奇怪的事情:job整体并行度为5的情况下,数据结果只往partition 0里写。然后把partitoner用null替代之后是以roundrobin方式写入每一个partition。感到很奇怪啊。求助 发自我的iPhone 发自我的iPhone |
|
|
In reply to this post by x2009438
FlinkFixedPartitioner就是往固定partition写,所有subTask搜写到一个partition,partitoner设置为null之后用的是kafka自己的partitoner,就是roundrobin
------------------ 原始邮件 ------------------ 发件人: "x2009438"<[hidden email]>; 发送时间: 2020年8月17日(星期一) 晚上10:03 收件人: "user-zh"<[hidden email]>; 主题: 1.11 kafka producer 只往一个partition里写 我看1.11的kafka默认是用FlinkFixedPartitioner,应该是把sink每个subtask里的数据全部写到某一个partition吧?但是碰到了一个奇怪的事情:job整体并行度为5的情况下,数据结果只往partition 0里写。然后把partitoner用null替代之后是以roundrobin方式写入每一个partition。感到很奇怪啊。求助 发自我的iPhone 发自我的iPhone |
|
|
In reply to this post by cs
是的,我看了一下源码。
因为我用的是simplestringschema,不属于keyedschema。所以flinkfixedpartitioner的open方法被跳过了,没有初始化subtask index,所以全部是0%partition=0,于是都写到partition 0里去了。 我感觉怪怪的,不太合逻辑。 发自我的iPhone >> 在 2020年8月17日,23:28,cs <[hidden email]> 写道: > 目前Kafka producer的partitioner使用的是org.apache.flink.streaming.connectors.kafka.partitioner.FlinkFixedPartitioner这个类 > 具体的分区方法是org.apache.flink.streaming.connectors.kafka.partitioner.FlinkFixedPartitioner#partition > 由该方法可以得知你每个subtask发到哪个kafka的partition中。每个subtask的数据只会写到一个固定的partition里面。 > > > > > ------------------ 原始邮件 ------------------ > 发件人: "user-zh" <[hidden email]>; > 发送时间: 2020年8月17日(星期一) 晚上10:03 > 收件人: "user-zh"<[hidden email]>; > > 主题: 1.11 kafka producer 只往一个partition里写 > > > > 我看1.11的kafka默认是用FlinkFixedPartitioner,应该是把sink每个subtask里的数据全部写到某一个partition吧?但是碰到了一个奇怪的事情:job整体并行度为5的情况下,数据结果只往partition 0里写。然后把partitoner用null替代之后是以roundrobin方式写入每一个partition。感到很奇怪啊。求助 > > > > > 发自我的iPhone > > > 发自我的iPhone |
|
|
org.apache.flink.streaming.connectors.kafka.partitioner.FlinkFixedPartitioner#open 方法和simplestringschema没有关系的。
这个open方法的调用你看下org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducerBase#open这个方法 我怀疑你是不是只有一个subtask里面有数据呢?你在sink之前rebalance一下看看呢 ------------------ 原始邮件 ------------------ 发件人: "user-zh" <[hidden email]>; 发送时间: 2020年8月18日(星期二) 中午12:50 收件人: "user-zh"<[hidden email]>; 主题: Re: 1.11 kafka producer 只往一个partition里写 是的,我看了一下源码。 因为我用的是simplestringschema,不属于keyedschema。所以flinkfixedpartitioner的open方法被跳过了,没有初始化subtask index,所以全部是0%partition=0,于是都写到partition 0里去了。 我感觉怪怪的,不太合逻辑。 发自我的iPhone >> 在 2020年8月17日,23:28,cs <[hidden email]> 写道: > 目前Kafka producer的partitioner使用的是org.apache.flink.streaming.connectors.kafka.partitioner.FlinkFixedPartitioner这个类 > 具体的分区方法是org.apache.flink.streaming.connectors.kafka.partitioner.FlinkFixedPartitioner#partition > 由该方法可以得知你每个subtask发到哪个kafka的partition中。每个subtask的数据只会写到一个固定的partition里面。 > > > > > ------------------&nbsp;原始邮件&nbsp;------------------ > 发件人: "user-zh" <[hidden email]&gt;; > 发送时间:&nbsp;2020年8月17日(星期一) 晚上10:03 > 收件人:&nbsp;"user-zh"<[hidden email]&gt;; > > 主题:&nbsp;1.11 kafka producer 只往一个partition里写 > > > > 我看1.11的kafka默认是用FlinkFixedPartitioner,应该是把sink每个subtask里的数据全部写到某一个partition吧?但是碰到了一个奇怪的事情:job整体并行度为5的情况下,数据结果只往partition 0里写。然后把partitoner用null替代之后是以roundrobin方式写入每一个partition。感到很奇怪啊。求助 > > > > > 发自我的iPhone > > > 发自我的iPhone |
|
|
您好, 首先十分感谢您! 我想FlinkFixedPartitioner的本意应该是把一个sink subtask里的数据写到同一个特定的kafka partition里,而不是把所有数据只写到一个partition里吧? 请看下面代码截图,我粗浅的理解是这样的,如果传入的不是keyedSchema(比如SimpleStringSchema)那么partitioner会被置为null,所以图一内的open方法不执行。parallelInstanceId=0,所以只往partition 0写。 我猜测如果传入一个keyedSchema,那么open方法会被执行。往mod余数的partitions里写。 又看了一下1.10的代码,似乎所有kafkaSchema会先被wrap成keyschema,所以没出现这个问题。 不如不是有意为之,那感觉是个bug? 代码能力比较初级,请指教!谢谢 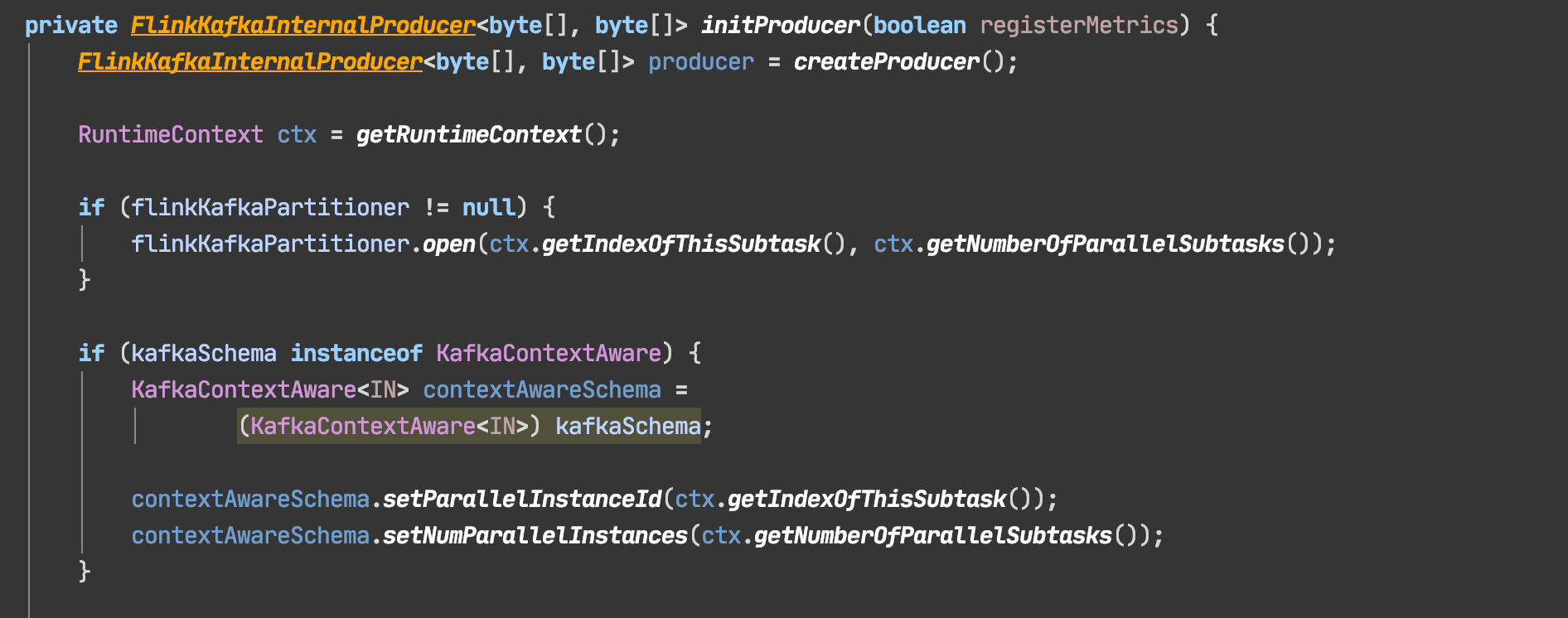 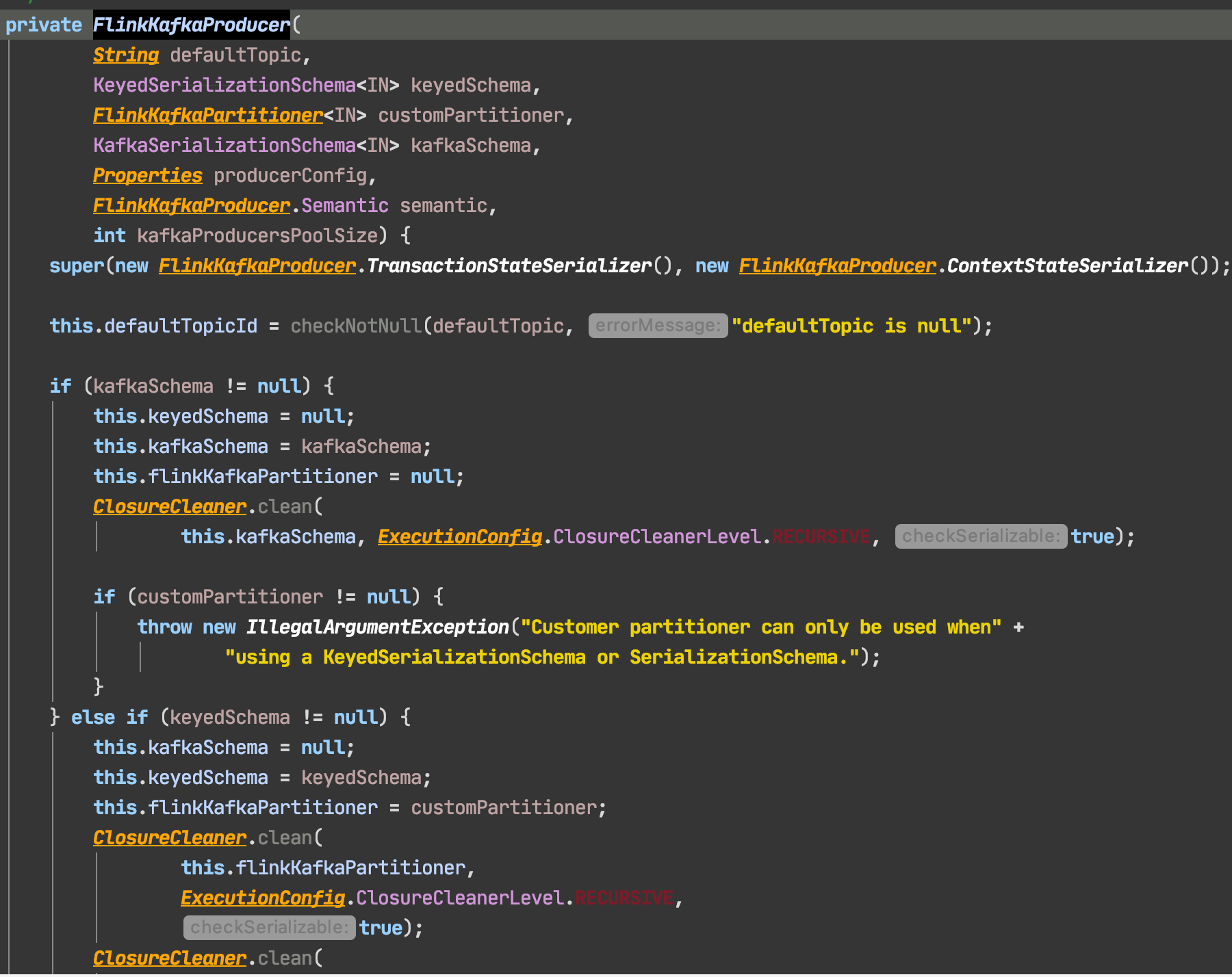
|
|
|
看不到你得图片哎,你用的是flink1.11吗 ------------------ 原始邮件 ------------------ 发件人: "user-zh" <[hidden email]>; 发送时间: 2020年8月18日(星期二) 下午2:22 收件人: "user-zh"<[hidden email]>; 抄送: "cs"<[hidden email]>; 主题: Re: 1.11 kafka producer 只往一个partition里写 您好, 首先十分感谢您! 我想FlinkFixedPartitioner的本意应该是把一个sink subtask里的数据写到同一个特定的kafka partition里,而不是把所有数据只写到一个partition里吧? 请看下面代码截图,我粗浅的理解是这样的,如果传入的不是keyedSchema(比如SimpleStringSchema)那么partitioner会被置为null,所以图一内的open方法不执行。parallelInstanceId=0,所以只往partition 0写。 我猜测如果传入一个keyedSchema,那么open方法会被执行。往mod余数的partitions里写。 又看了一下1.10的代码,似乎所有kafkaSchema会先被wrap成keyschema,所以没出现这个问题。 不如不是有意为之,那感觉是个bug? 代码能力比较初级,请指教!谢谢
|
|
|
是的,1.11.1。 图片挂了,我复制下代码。谢谢 ==================================================================================== private FlinkKafkaInternalProducer<byte[], byte[]> initProducer(boolean registerMetrics) { FlinkKafkaInternalProducer<byte[], byte[]> producer = createProducer(); RuntimeContext ctx = getRuntimeContext(); if (flinkKafkaPartitioner != null) { flinkKafkaPartitioner.open(ctx.getIndexOfThisSubtask(), ctx.getNumberOfParallelSubtasks()); } if (kafkaSchema instanceof KafkaContextAware) { KafkaContextAware<IN> contextAwareSchema = (KafkaContextAware<IN>) kafkaSchema; contextAwareSchema.setParallelInstanceId(ctx.getIndexOfThisSubtask()); contextAwareSchema.setNumParallelInstances(ctx.getNumberOfParallelSubtasks()); } =================================================================== private FlinkKafkaProducer( String defaultTopic, KeyedSerializationSchema<IN> keyedSchema, FlinkKafkaPartitioner<IN> customPartitioner, KafkaSerializationSchema<IN> kafkaSchema, Properties producerConfig, FlinkKafkaProducer.Semantic semantic, int kafkaProducersPoolSize) { super(new FlinkKafkaProducer.TransactionStateSerializer(), new FlinkKafkaProducer.ContextStateSerializer()); this.defaultTopicId = checkNotNull(defaultTopic, "defaultTopic is null"); if (kafkaSchema != null) { this.keyedSchema = null; this.kafkaSchema = kafkaSchema; this.flinkKafkaPartitioner = null; ClosureCleaner.clean( this.kafkaSchema, ExecutionConfig.ClosureCleanerLevel.RECURSIVE, true); if (customPartitioner != null) { throw new IllegalArgumentException("Customer partitioner can only be used when" + "using a KeyedSerializationSchema or SerializationSchema."); } } else if (keyedSchema != null) { this.kafkaSchema = null; this.keyedSchema = keyedSchema; this.flinkKafkaPartitioner = customPartitioner; ClosureCleaner.clean( this.flinkKafkaPartitioner, ExecutionConfig.ClosureCleanerLevel.RECURSIVE, true); ClosureCleaner.clean( this.keyedSchema, ExecutionConfig.ClosureCleanerLevel.RECURSIVE, true); } else { throw new IllegalArgumentException( "You must provide either a KafkaSerializationSchema or a" + "KeyedSerializationSchema."); } 在 2020-08-18 13:33:38,"cs" <[hidden email]> 写道: 看不到你得图片哎,你用的是flink1.11吗 ------------------ 原始邮件 ------------------ 发件人: "user-zh" <[hidden email]>; 发送时间: 2020年8月18日(星期二) 下午2:22 收件人: "user-zh"<[hidden email]>; 抄送: "cs"<[hidden email]>; 主题: Re: 1.11 kafka producer 只往一个partition里写 您好, 首先十分感谢您! 我想FlinkFixedPartitioner的本意应该是把一个sink subtask里的数据写到同一个特定的kafka partition里,而不是把所有数据只写到一个partition里吧? 请看下面代码截图,我粗浅的理解是这样的,如果传入的不是keyedSchema(比如SimpleStringSchema)那么partitioner会被置为null,所以图一内的open方法不执行。parallelInstanceId=0,所以只往partition 0写。 我猜测如果传入一个keyedSchema,那么open方法会被执行。往mod余数的partitions里写。 又看了一下1.10的代码,似乎所有kafkaSchema会先被wrap成keyschema,所以没出现这个问题。 不如不是有意为之,那感觉是个bug? 代码能力比较初级,请指教!谢谢 On Aug 18, 2020, at 13:41, cs <[hidden email]> wrote: org.apache.flink.streaming.connectors.kafka.partitioner.FlinkFixedPartitioner#open 方法和simplestringschema没有关系的。 这个open方法的调用你看下org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducerBase#open这个方法 我怀疑你是不是只有一个subtask里面有数据呢?你在sink之前rebalance一下看看呢 ------------------ 原始邮件 ------------------ 发件人: "user-zh" <[hidden email]>; 发送时间: 2020年8月18日(星期二) 中午12:50 收件人: "user-zh"<[hidden email]>; 主题: Re: 1.11 kafka producer 只往一个partition里写 是的,我看了一下源码。 因为我用的是simplestringschema,不属于keyedschema。所以flinkfixedpartitioner的open方法被跳过了,没有初始化subtask index,所以全部是0%partition=0,于是都写到partition 0里去了。 我感觉怪怪的,不太合逻辑。 发自我的iPhone >> 在 2020年8月17日,23:28,cs <[hidden email]> 写道: > 目前Kafka producer的partitioner使用的是org.apache.flink.streaming.connectors.kafka.partitioner.FlinkFixedPartitioner这个类 > 具体的分区方法是org.apache.flink.streaming.connectors.kafka.partitioner.FlinkFixedPartitioner#partition > 由该方法可以得知你每个subtask发到哪个kafka的partition中。每个subtask的数据只会写到一个固定的partition里面。 > > > > > ------------------&nbsp;原始邮件&nbsp;------------------ > 发件人: "user-zh" <[hidden email]&gt;; > 发送时间:&nbsp;2020年8月17日(星期一) 晚上10:03 > 收件人:&nbsp;"user-zh"<[hidden email]&gt;; > > 主题:&nbsp;1.11 kafka producer 只往一个partition里写 > > > > 我看1.11的kafka默认是用FlinkFixedPartitioner,应该是把sink每个subtask里的数据全部写到某一个partition吧?但是碰到了一个奇怪的事情:job整体并行度为5的情况下,数据结果只往partition 0里写。然后把partitoner用null替代之后是以roundrobin方式写入每一个partition。感到很奇怪啊。求助 > > > > > 发自我的iPhone > > > 发自我的iPhone |
|
|
我看了下,你应该用的是 flink-connector-kafka_2.12 这个依赖包吧
这个的确会出现你说的情况,发到一个分区。 建议使用flink-connector-kafka-{kafka版本} 例如flink-connector-kafka-0.8 ------------------ 原始邮件 ------------------ 发件人: "user-zh" <[hidden email]>; 发送时间: 2020年8月18日(星期二) 下午2:41 收件人: "user-zh"<[hidden email]>;"cs"<[hidden email]>; 主题: Re:回复: 1.11 kafka producer 只往一个partition里写 是的,1.11.1。 图片挂了,我复制下代码。谢谢 ==================================================================================== private FlinkKafkaInternalProducer<byte[], byte[]> initProducer(boolean registerMetrics) { FlinkKafkaInternalProducer<byte[], byte[]> producer = createProducer(); RuntimeContext ctx = getRuntimeContext(); if (flinkKafkaPartitioner != null) { flinkKafkaPartitioner.open(ctx.getIndexOfThisSubtask(), ctx.getNumberOfParallelSubtasks()); } if (kafkaSchema instanceof KafkaContextAware) { KafkaContextAware<IN> contextAwareSchema = (KafkaContextAware<IN>) kafkaSchema; contextAwareSchema.setParallelInstanceId(ctx.getIndexOfThisSubtask()); contextAwareSchema.setNumParallelInstances(ctx.getNumberOfParallelSubtasks()); } =================================================================== private FlinkKafkaProducer( String defaultTopic, KeyedSerializationSchema<IN> keyedSchema, FlinkKafkaPartitioner<IN> customPartitioner, KafkaSerializationSchema<IN> kafkaSchema, Properties producerConfig, FlinkKafkaProducer.Semantic semantic, int kafkaProducersPoolSize) { super(new FlinkKafkaProducer.TransactionStateSerializer(), new FlinkKafkaProducer.ContextStateSerializer()); this.defaultTopicId = checkNotNull(defaultTopic, "defaultTopic is null"); if (kafkaSchema != null) { this.keyedSchema = null; this.kafkaSchema = kafkaSchema; this.flinkKafkaPartitioner = null; ClosureCleaner.clean( this.kafkaSchema, ExecutionConfig.ClosureCleanerLevel.RECURSIVE, true); if (customPartitioner != null) { throw new IllegalArgumentException("Customer partitioner can only be used when" + "using a KeyedSerializationSchema or SerializationSchema."); } } else if (keyedSchema != null) { this.kafkaSchema = null; this.keyedSchema = keyedSchema; this.flinkKafkaPartitioner = customPartitioner; ClosureCleaner.clean( this.flinkKafkaPartitioner, ExecutionConfig.ClosureCleanerLevel.RECURSIVE, true); ClosureCleaner.clean( this.keyedSchema, ExecutionConfig.ClosureCleanerLevel.RECURSIVE, true); } else { throw new IllegalArgumentException( "You must provide either a KafkaSerializationSchema or a" + "KeyedSerializationSchema."); } 在 2020-08-18 13:33:38,"cs" <[hidden email]> 写道: 看不到你得图片哎,你用的是flink1.11吗 ------------------ 原始邮件 ------------------ 发件人: "user-zh" <[hidden email]>; 发送时间: 2020年8月18日(星期二) 下午2:22 收件人: "user-zh"<[hidden email]>; 抄送: "cs"<[hidden email]>; 主题: Re: 1.11 kafka producer 只往一个partition里写 您好, 首先十分感谢您! 我想FlinkFixedPartitioner的本意应该是把一个sink subtask里的数据写到同一个特定的kafka partition里,而不是把所有数据只写到一个partition里吧? 请看下面代码截图,我粗浅的理解是这样的,如果传入的不是keyedSchema(比如SimpleStringSchema)那么partitioner会被置为null,所以图一内的open方法不执行。parallelInstanceId=0,所以只往partition 0写。 我猜测如果传入一个keyedSchema,那么open方法会被执行。往mod余数的partitions里写。 又看了一下1.10的代码,似乎所有kafkaSchema会先被wrap成keyschema,所以没出现这个问题。 不如不是有意为之,那感觉是个bug? 代码能力比较初级,请指教!谢谢 On Aug 18, 2020, at 13:41, cs <[hidden email]> wrote: org.apache.flink.streaming.connectors.kafka.partitioner.FlinkFixedPartitioner#open 方法和simplestringschema没有关系的。 这个open方法的调用你看下org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducerBase#open这个方法 我怀疑你是不是只有一个subtask里面有数据呢?你在sink之前rebalance一下看看呢 ------------------&nbsp;原始邮件&nbsp;------------------ 发件人: "user-zh" <[hidden email]&gt;; 发送时间:&nbsp;2020年8月18日(星期二) 中午12:50 收件人:&nbsp;"user-zh"<[hidden email]&gt;; 主题:&nbsp;Re: 1.11 kafka producer 只往一个partition里写 是的,我看了一下源码。 因为我用的是simplestringschema,不属于keyedschema。所以flinkfixedpartitioner的open方法被跳过了,没有初始化subtask index,所以全部是0%partition=0,于是都写到partition 0里去了。 我感觉怪怪的,不太合逻辑。 发自我的iPhone &gt;&gt; 在 2020年8月17日,23:28,cs <[hidden email]&gt; 写道: &gt; 目前Kafka producer的partitioner使用的是org.apache.flink.streaming.connectors.kafka.partitioner.FlinkFixedPartitioner这个类 &gt; 具体的分区方法是org.apache.flink.streaming.connectors.kafka.partitioner.FlinkFixedPartitioner#partition &gt; 由该方法可以得知你每个subtask发到哪个kafka的partition中。每个subtask的数据只会写到一个固定的partition里面。 &gt; &gt; &gt; &gt; &gt; ------------------&amp;nbsp;原始邮件&amp;nbsp;------------------ &gt; 发件人:&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp; "user-zh"&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp;&nbsp; <[hidden email]&amp;gt;; &gt; 发送时间:&amp;nbsp;2020年8月17日(星期一) 晚上10:03 &gt; 收件人:&amp;nbsp;"user-zh"<[hidden email]&amp;gt;; &gt; &gt; 主题:&amp;nbsp;1.11 kafka producer 只往一个partition里写 &gt; &gt; &gt; &gt; 我看1.11的kafka默认是用FlinkFixedPartitioner,应该是把sink每个subtask里的数据全部写到某一个partition吧?但是碰到了一个奇怪的事情:job整体并行度为5的情况下,数据结果只往partition 0里写。然后把partitoner用null替代之后是以roundrobin方式写入每一个partition。感到很奇怪啊。求助 &gt; &gt; &gt; &gt; &gt; 发自我的iPhone &gt; &gt; &gt; 发自我的iPhone |
«
Return to Apache Flink 中文用户邮件列表
|
1 view|%1 views
| Free forum by Nabble | Edit this page |